Sumber pengetahuan AI membantu fitur AI kami seperti Agen AI dan AI Assist memberikan respons yang akurat menggunakan konten bisnis Anda—FAQ, dokumentasi, dan panduan bantuan. Panduan ini menjelaskan cara menambahkan, mengelola, dan mengoptimalkan sumber pengetahuan untuk kinerja agen yang lebih baik.
Jenis file dan format tautan yang didukung
Anda dapat menambahkan konten terstruktur dan tidak terstruktur sebagai sumber pengetahuan.
Format yang didukung meliputi:
Dokumen: .pdf, .txt, .md, .csv, .docx, .pptx, .ppsx
Gambar: .jpeg, .png, .bmp, .webp, .tiff
Tautan: URL halaman web publik
Menambahkan sumber pengetahuan
Sumber pengetahuan adalah data utama yang digunakan oleh Agen AI dan AI Assist untuk menghasilkan respons yang bermanfaat dan berdasarkan konteks. Ini diindeks secara otomatis dan biasanya siap digunakan dalam beberapa menit.
Anda dapat menambahkan atau mengelola sumber pengetahuan dari lokasi-lokasi ini:
Agen AI > Kelola sumber pengetahuan
Agen AI > Pilih template atau mulai dari awal > Tambahkan sumber pengetahuan
Pengaturan Workspace > AI Assist > Kelola sumber pengetahuan
Dari lokasi-lokasi ini, Anda dapat:
Unggah file
Seret dan lepas beberapa file yang didukung: .pdf, .txt, .md, .csv, .docx, .pptx, .ppsx, dan format gambar (.jpeg, .png, .bmp, .webp, .tiff).
Anda dapat mengupload hingga 5 file sekaligus, dengan maksimum 100 sumber pengetahuan berbasis file per workspace.
Batas ukuran file: 20MB per file.
Penting: Paket percobaan memiliki batas ukuran 1MB per file sementara paket berbayar mengizinkan hingga 20MB per file.
Tambahkan URL situs web
Tempelkan URL halaman web publik di bidang Website URLs.
Secara default, crawler berjalan 3 tingkat dalam tetapi dapat disesuaikan hingga 100 tingkat.
Anda dapat menambahkan hingga 5 URL tambahan di bawah satu sumber pengetahuan situs web.
Klik Resync untuk menyegarkan konten atau menetapkan jadwal sinkronisasi otomatis untuk menjaga agar tetap diperbarui.
Anda dapat mengupload hingga 3 sumber pengetahuan secara paralel (file atau URL situs web) — tidak perlu menunggu satu selesai sebelum memulai yang lain.
Pantau status
Setiap sumber pengetahuan menampilkan status:
Selesai – Siap digunakan
Dalam Proses – Memproses atau mengindeks
Kesalahan – Butuh perbaikan (misalnya, file tidak bisa dibaca, crawl terblokir)
Sebagian Selesai – Beberapa konten disimpan, tetapi pemrosesan mencapai batas atau waktu habis
Pelajari lebih lanjut tentang menggunakan sumber pengetahuan dengan AI Assist di sini.
Pengaturan lanjutan (untuk sumber pengetahuan situs web)
Saat menambahkan atau mengedit sumber pengetahuan situs web, Anda dapat menyempurnakan perilaku crawling dalam Pengaturan Lanjutan:
Sertakan URL dari sitemap
Ini diaktifkan secara default. Gunakan ini jika Anda ingin merayapi lebih banyak URL, termasuk halaman yang tidak terhubung dari URL situs web yang Anda tambahkan.
Anda juga dapat menambahkan sitemap secara manual sebagai URL (misalnya, https://example.com/sitemap.xml).
Halaman dari sitemap mulai pada kedalaman crawl 1, dan sitemap besar mungkin memerlukan waktu lebih lama untuk di-crawl.
URL tambahan (opsional): Tambahkan hingga 5 titik masuk tambahan.
Maks kedalaman crawling
Tetapkan berapa banyak tingkat tautan yang akan diikuti. Misalnya, 0 berarti hanya URL yang disediakan yang dirayapi dan 1 termasuk halaman yang terhubung langsung.
Nilai yang lebih tinggi memungkinkan crawling yang lebih dalam. Kedalaman crawl diatur ke 3 secara default.
Sertakan URL globs (opsional):
Tentukan pola URL untuk halaman yang ingin Anda masukkan dalam crawling oleh penyusup.
Ini hanya berlaku untuk tautan yang ditemukan di halaman—bukan Website URLs yang telah Anda masukkan. Untuk memastikan halaman tertentu dirayapi, tambahkan URL-nya langsung di bawah Website URLs.
Kecualikan URL globs (opsional):
Gunakan ini untuk mengecualikan URL tertentu dari crawling.
Ini hanya berlaku untuk tautan yang ditemukan di halaman—bukan Website URLs, yang selalu dirayapi.
Apa itu URL globs?
glob adalah pola yang dapat Anda gunakan untuk memberi tahu crawler halaman mana yang harus disertakan atau dilewati, tanpa mencantumkan setiap URL satu per satu.
*(asterisk tunggal) hanya mencakup satu tingkat halaman.**(asterisk ganda) mencakup semua tingkat, termasuk subhalaman yang lebih dalam.
Sertakan globs
Contoh yang benar:
https://example.com/docs/*→ Hanya menyertakan halaman yang langsung berada di bawah/docs/(seperti/docs/page1), tetapi tidak jalur yang lebih dalam.https://example.com/help/**→ Menyertakan semuanya di bawah/help/, termasuk subfolder dan halaman bersarang (seperti/help/tutorials/page1).
Contoh yang salah:
https://example.com/*help*→ Tidak akan berfungsi sesuai yang diharapkan. Single * hanya cocok dalam satu segmen jalur, bukan di seluruh folder.example.com/**→ Hilang protokol https://, yang mungkin ditolak oleh crawler.
Kecualikan globs
Contoh yang benar:
https://example.com/docs/*→ Hanya melewati halaman segera di bawah/docs/(seperti/docs/page1), tetapi tidak akan melewati yang lebih dalam.https://example.com/archive/**→ Melewati semuanya di bawah/archive/, termasuk folder bersarang dan subhalaman.
Contoh lainnya yang benar:
https://example.com/**?foo=*→ Melewati URL mana pun diexample.comyang mengandung parameter kuerifoo.
Contoh yang salah:
/*?foo=*→ Terlalu luas; dapat secara tidak sengaja melewati halaman di seluruh domain. Selalu sertakan domain Anda (misalnya,https://example.com/**?foo=*).https://example.com/ (tanpa/**) → Hanya mengecualikan beranda, bukan subhalaman.
Mengapa menggunakan globs?
Globs sangat berguna ketika situs web Anda berisi campuran halaman bermanfaat dan tidak bermanfaat untuk pelatihan AI. Mereka memberi Anda lebih banyak kontrol untuk:
Hemat waktu: Alih-alih menambahkan puluhan URL serupa satu per satu, sertakan semuanya dengan pola tunggal.
Kurangi kebisingan: Kecualikan bagian yang tidak relevan (misalnya, halaman pemasaran, arsip blog, atau halaman login) sehingga AI hanya fokus pada konten terkait bantuan, misalnya.
Menangani situs yang kompleks: Untuk pusat bantuan besar atau pengaturan multi-domain, globs memastikan jangkauan bagian yang relevan tanpa menyinkronkan materi yang tidak terkait.
Cegah kesalahan: Dengan mengecualikan URL yang bermasalah atau tidak relevan (seperti lingkungan staging atau arsip yang sudah kedaluwarsa), Anda mengurangi kegagalan crawl dan meningkatkan kualitas jawaban AI.
Tips untuk menulis globs yang efektif
Spesifiklah tapi jangan terlalu sempit:
https://example.com/help/**lebih baik daripadahttps://example.com/**, yang mungkin merayapi terlalu banyak konten yang tidak relevan.Gunakan kecualikan globs untuk pembersihan: Jika halaman bantuan Anda mengandung konten campuran, gunakan pola kecualikan (misalnya,
*/promo/**) untuk menyaring materi pemasaran.Hindari globs yang tumpang tindih: Aturan include dan exclude yang tumpang tindih dapat menyebabkan kebingungan. Selalu periksa pola untuk memastikan Anda tidak secara tidak sengaja melewati halaman penting.
Bagaimana Agen AI menggunakan sumber pengetahuan
Saat mengatur Agen AI—apakah Anda mulai dari template atau membangunnya dari awal—Anda dapat menghubungkan sumber pengetahuan yang relevan segera. Anda juga dapat mengelolanya nanti dengan pergi ke Agen AI > Kelola Sumber Pengetahuan.
Sumber pengetahuan digunakan untuk:
Menjawab pertanyaan produk dengan akurat
Memberikan konten bantuan dalam konteks
Menghindari halusinasi atau tebakan ketika Agen AI merespons
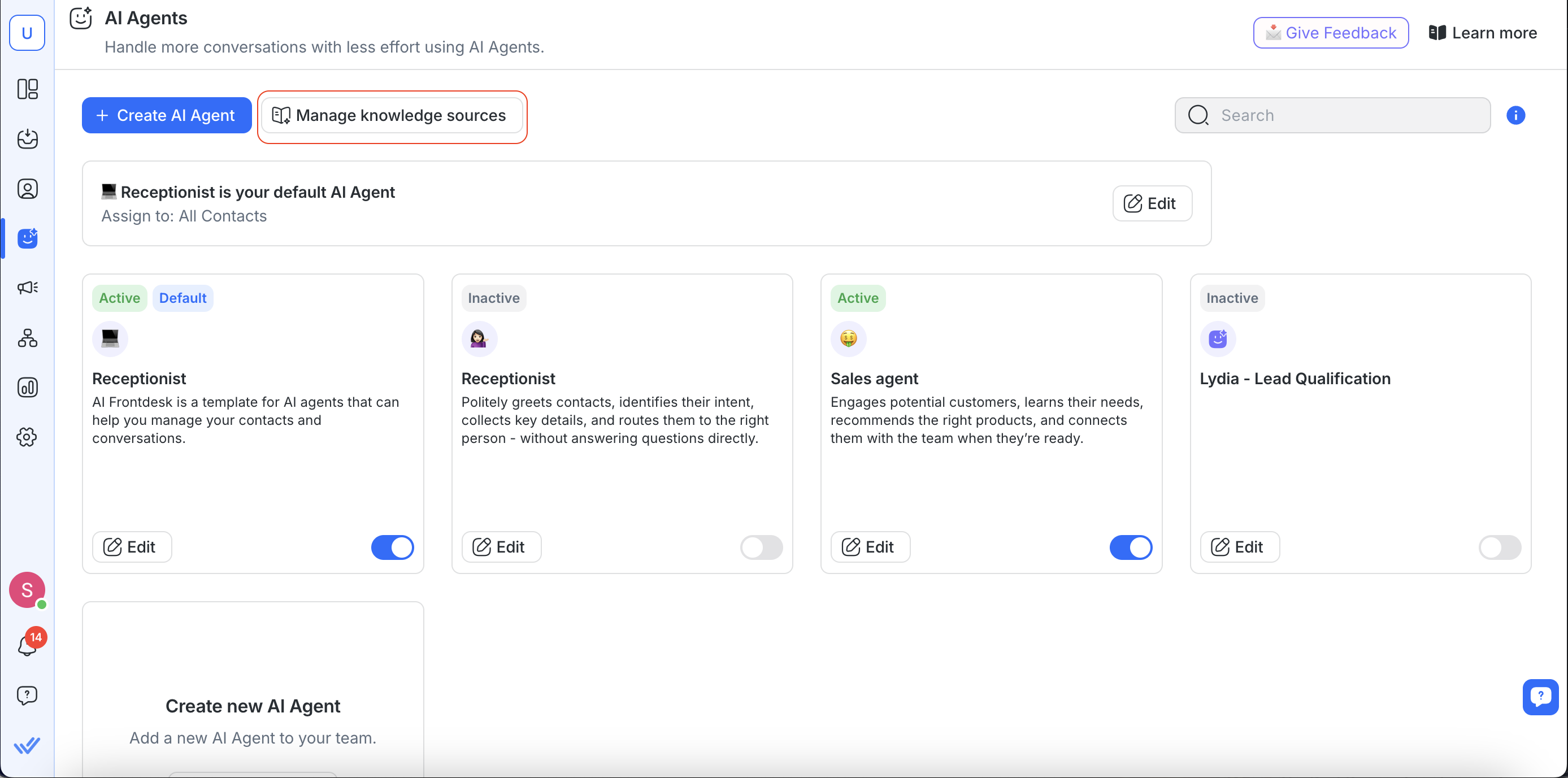
Saat membuat atau mengedit Agen AI:
Semua sumber pengetahuan yang tersedia tercantum untuk Anda tinjau.
Anda dapat mengaktifkan atau menonaktifkan sumber pengetahuan tertentu tergantung pada tujuan agen.
Setelah diaktifkan, Agen AI akan menggunakan sumber pengetahuan untuk memberitahukan jawabannya kepada Kontak.
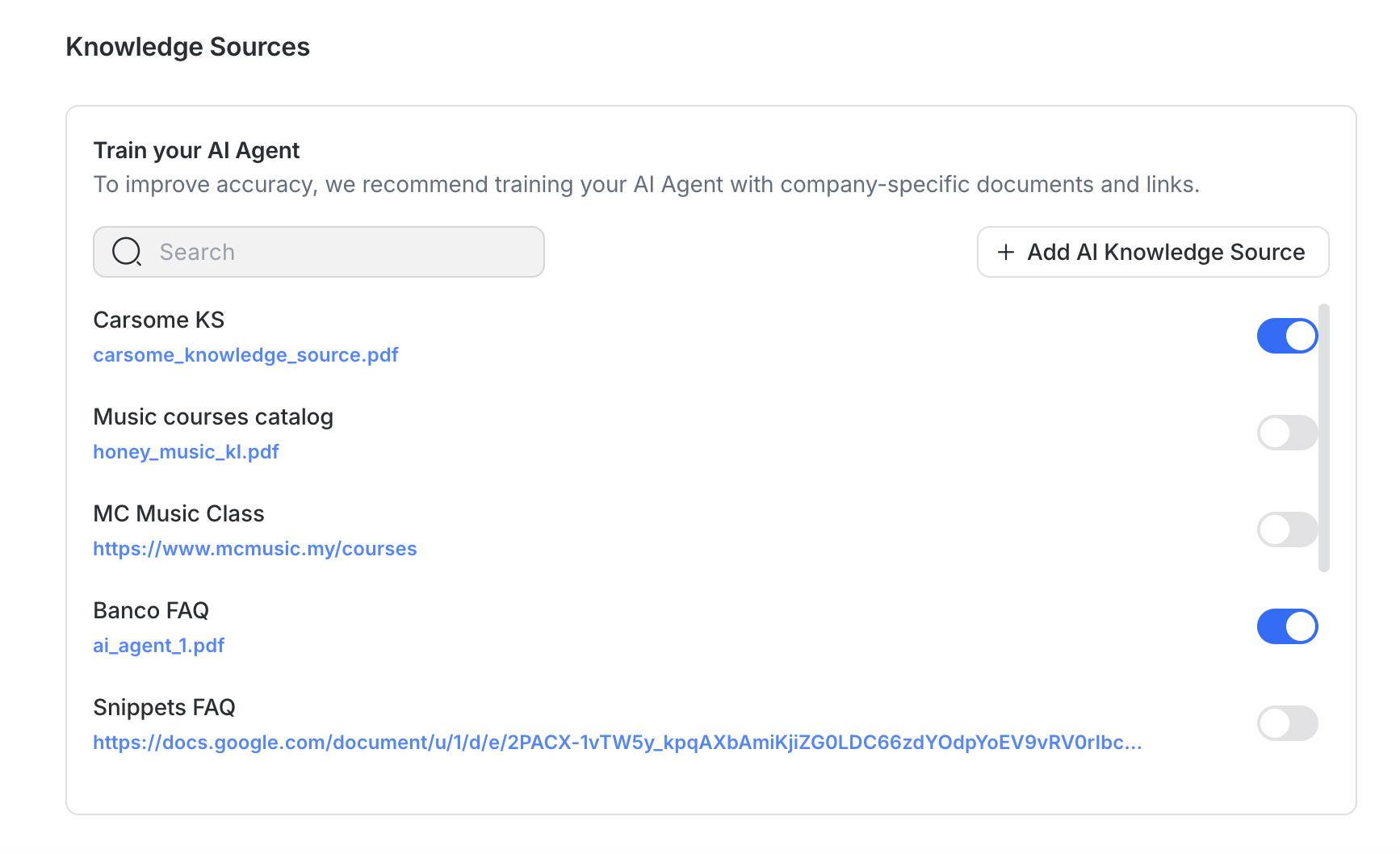
Untuk meningkatkan akurasi dan kualitas respons:
Gunakan sumber spesifik topik: Hindari menggabungkan banyak topik ke dalam satu file.
Batasi kebisingan: Hapus footer branding, penafian, atau informasi yang tidak relevan sebelum mengupload.
Saat menguji Agen AI, balasan mungkin menampilkan label “{#} sumber”. Ini memungkinkan Anda memverifikasi sumber pengetahuan mana yang digunakan untuk menghasilkan balasan. Klik label untuk meninjau sumber, atau pilih Kelola untuk memperbarui, menyinkronkan ulang, atau mengganti sumber pengetahuan secara langsung.
Mengelola sumber pengetahuan yang ada
Anda dapat memperbarui, mengganti, menyinkronkan ulang, atau menghapus sumber pengetahuan melalui halaman Sumber Pengetahuan AI.
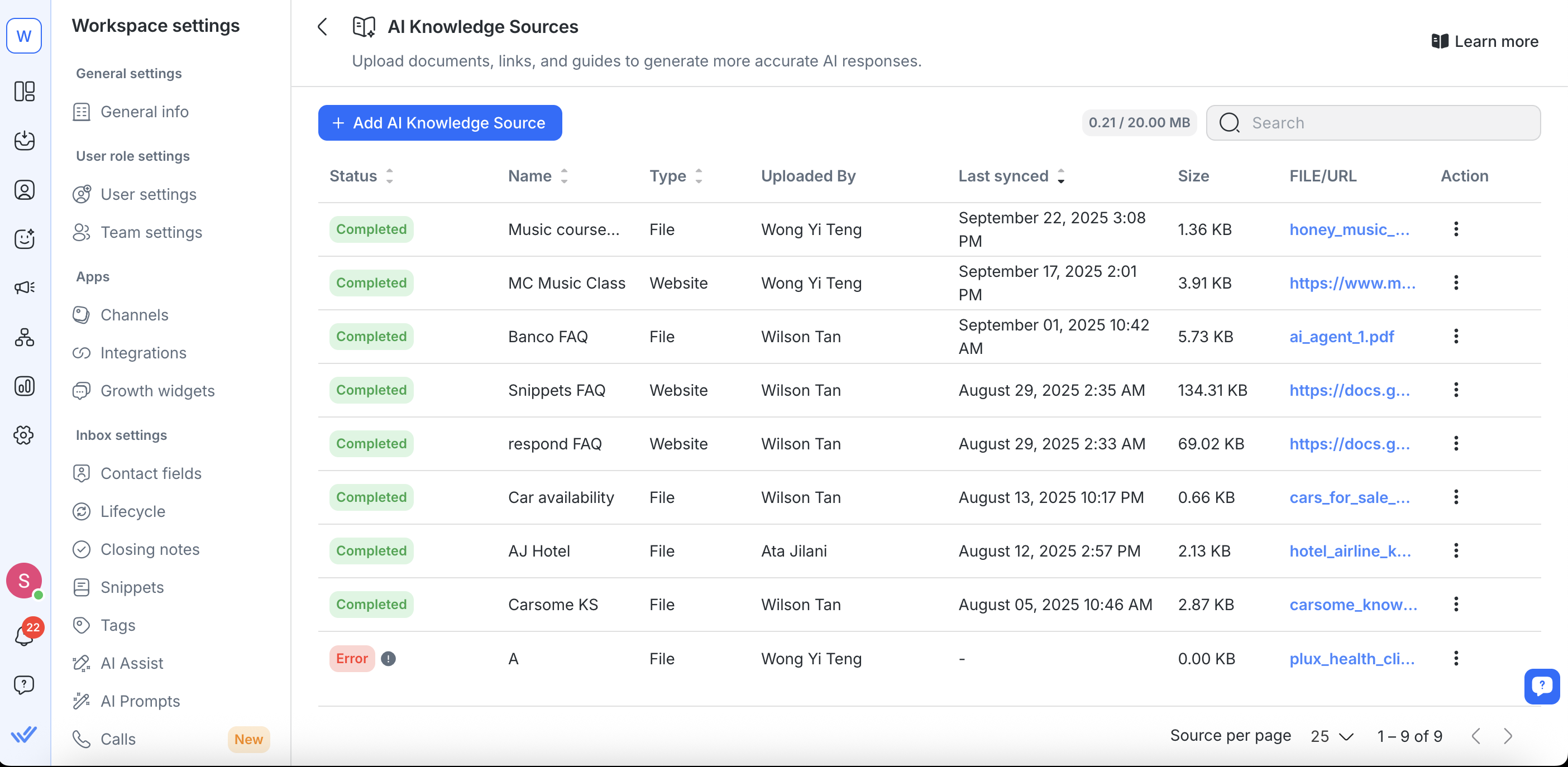
Keterbatasan:
Agen AI tidak dapat memprioritaskan atau memilih sumber pengetahuan. Mereka tidak dapat menentukan dokumen mana yang "terbaik" atau paling relevan sebagai sumber. Untuk memastikan balasan yang akurat, Anda harus memandu Agen AI dengan memberi tahu secara persis kata kunci apa yang harus dicari dalam sumber pengetahuan Anda.
Agen AI tidak dapat mencari berdasarkan judul dokumen, hanya berdasarkan kata kunci di dalam konten. Merujuk pada dokumen berdasarkan namanya (mis. "periksa Panduan Harga") tidak akan berhasil. Sebagai gantinya, instruksikan Agen AI untuk mencari istilah atau konsep tertentu dalam dokumen (mis. "cari kata kunci 'pricing options'").
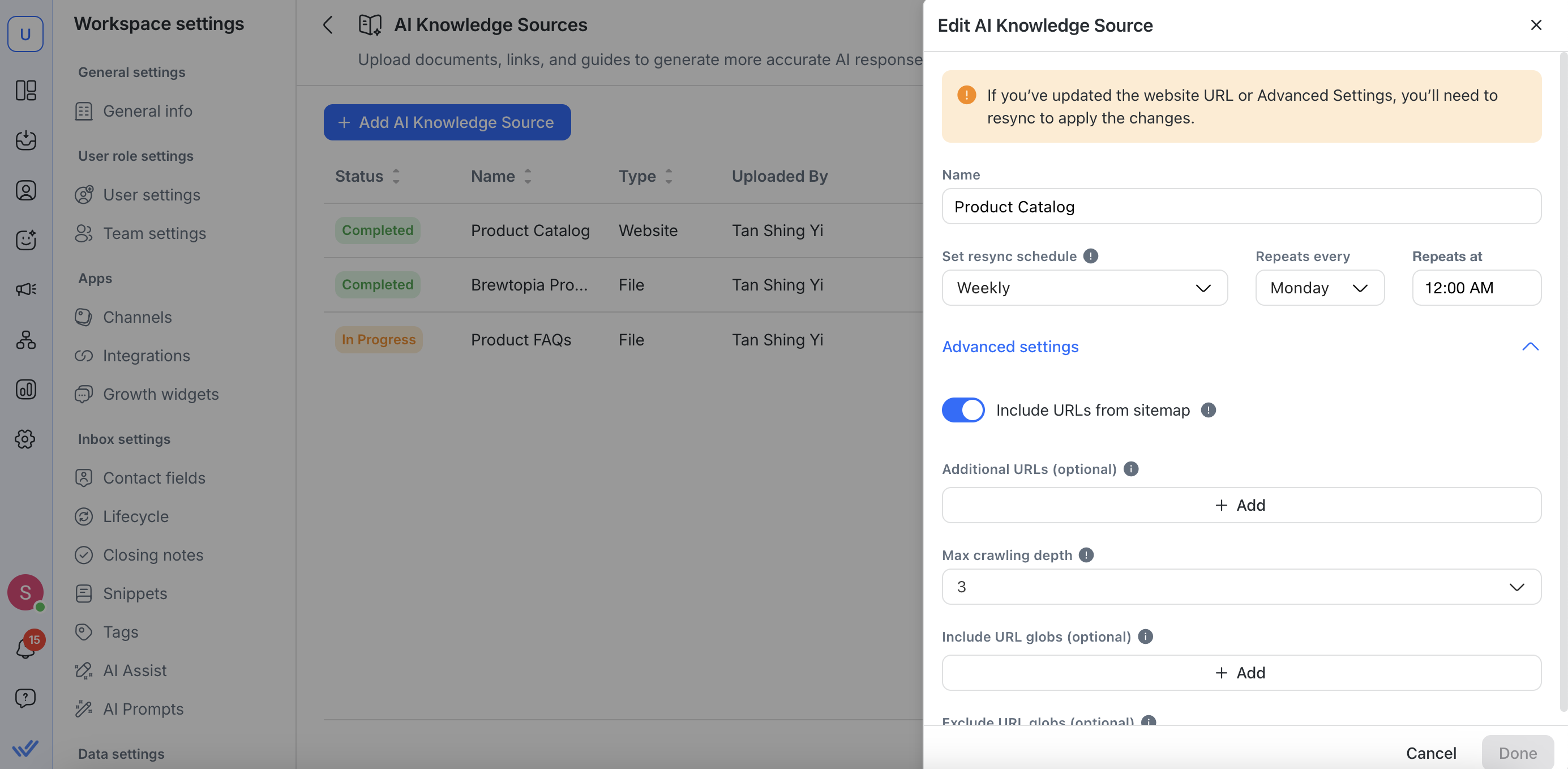
Edit sumber pengetahuan
Untuk mengedit file, Anda dapat:
Mengganti nama sumber pengetahuan Anda
Mengganti file yang diupload (misalnya, menukar PDF dengan versi .txt)
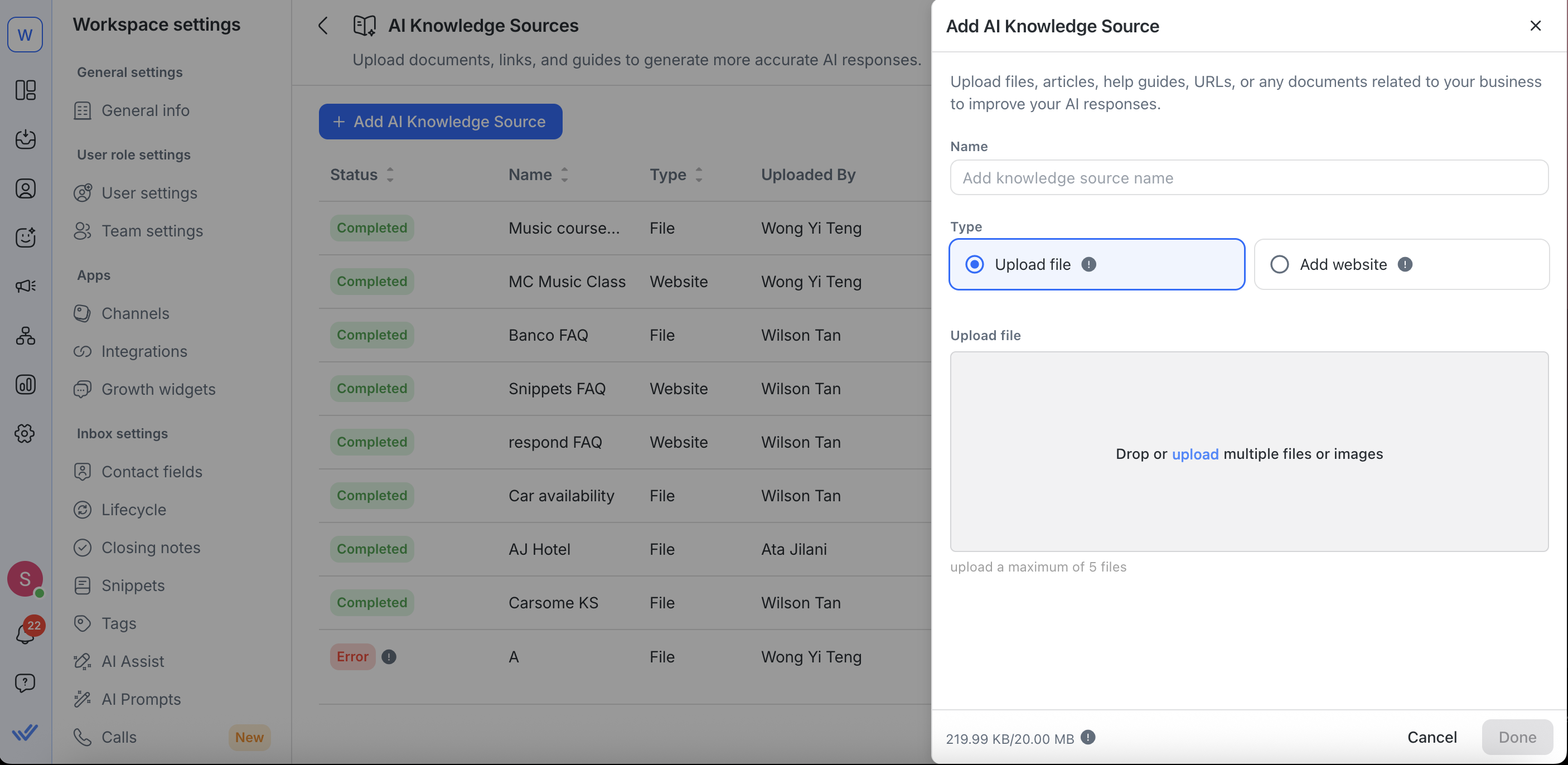
Untuk mengedit URL situs web, Anda dapat:
Ubah nama sumber pengetahuan Anda
Memperbarui URL Situs Web Anda
Menetapkan atau menyesuaikan jadwal penyinkronan ulang
Melakukan konfigurasi lebih lanjut di Pengaturan Lanjutan
Jika Anda memperbarui URL situs web atau melakukan perubahan di Pengaturan Lanjutan, Anda perlu menyinkronkan ulang sumber pengetahuan untuk menerapkan perubahan tersebut.
Hapus sumber pengetahuan
Hapus file atau URL yang tidak digunakan atau yang sudah kedaluwarsa untuk tetap dalam batas dan menjaga fitur AI Anda diperbarui dengan informasi yang paling akurat.
Klik Actions > Hapus
Sumber pengetahuan yang dihapus tidak akan lagi digunakan untuk menghasilkan balasan
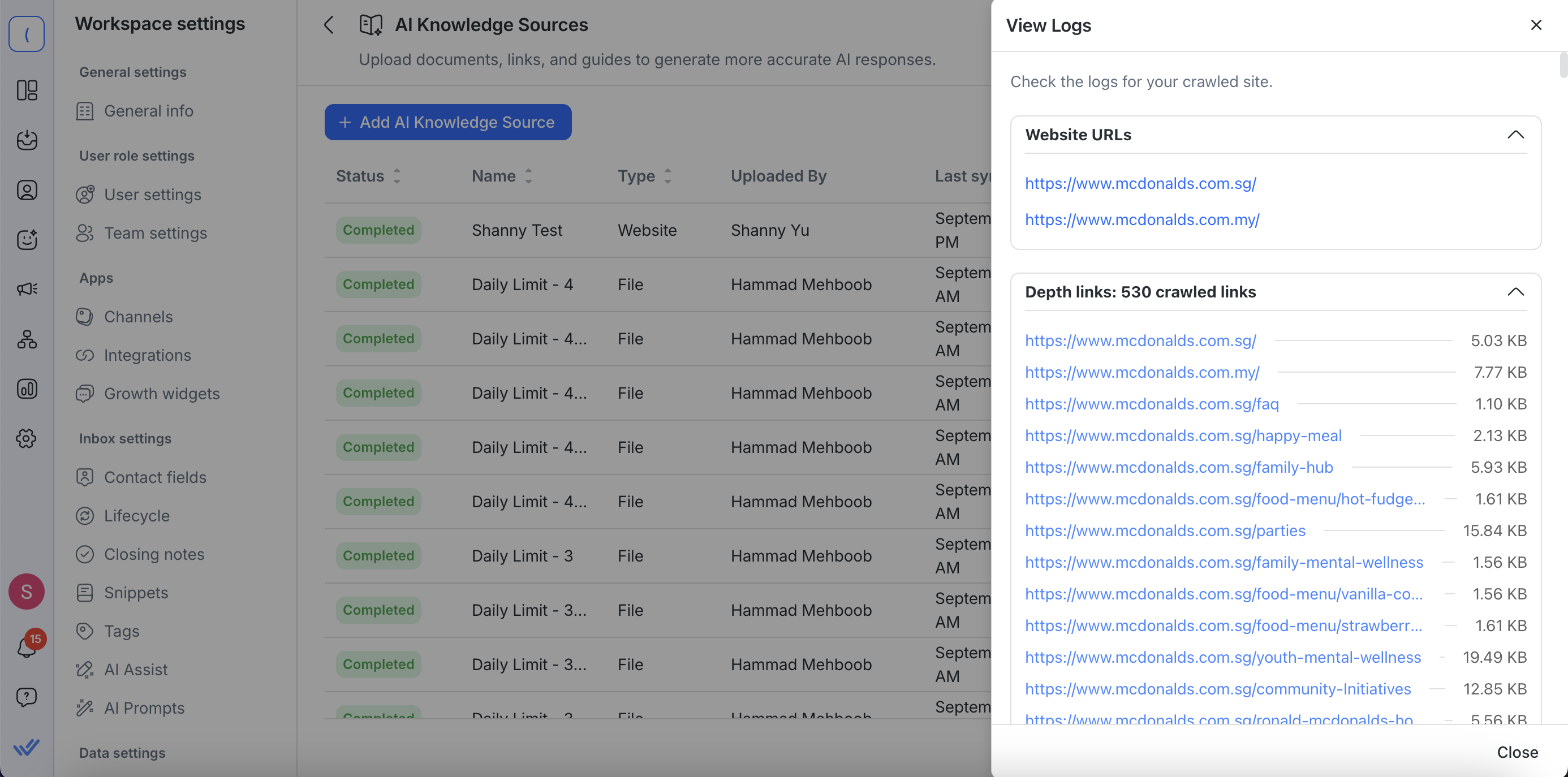
Lihat log (untuk URL web)
Klik Actions > Lihat Log untuk meninjau rincian crawling sumber pengetahuan situs web. Log memberikan Anda visibilitas penuh tentang apa yang ditangkap:
URL awal dan tambahan – Lihat URL situs web yang Anda masukkan bersama dengan URL tambahan yang ditambahkan di Pengaturan Lanjutan.
Daftar semua tautan yang dirayapi – Setiap URL yang dikunjungi ditampilkan.
Tautan yang dapat diklik — Setiap tautan yang dirayapi dibuka di tab baru sehingga Anda dapat melihat konten yang dirayapi secara langsung.
Ukuran konten yang diekstrak – Periksa seberapa banyak teks yang ditarik dari setiap halaman, ditampilkan dalam KB atau MB.
Ini memudahkan untuk memastikan bahwa halaman penting telah disertakan, mengidentifikasi konten yang hilang atau tidak relevan, dan memecahkan masalah mengenai crawls.
Penyinkronan ulang sumber situs web
Untuk menyegarkan konten web yang sudah kedaluwarsa:
Klik Actions > Resync di samping sumber situs web
Saat Anda mengklik Resync, prosesnya dimulai segera dan ikon muncul menunjukkan bahwa proses sedang berjalan.
Anda akan diberi tahu jika resinkronisasi tidak selesai sepenuhnya, seperti:
Mencapai batas karakter: sumber akan ditampilkan sebagai Selesai Sebagian, dan semua konten yang dipindai hingga batas akan disimpan
Kesalahan timeout atau koneksi: perayapan dapat berhenti lebih awal (paling lama 1 jam), dengan sebagian konten dipertahankan jika memungkinkan.
Resinkronisasi dinonaktifkan ketika sumber pengetahuan sedang disinkronisasi secara aktif.
Batas ruang kerja untuk sumber pengetahuan AI
Untuk menjaga agar semuanya berjalan lancar, ada batasan mengenai berapa banyak sumber pengetahuan yang dapat Anda tambahkan dan seberapa banyak konten yang dapat disimpan. Berikut adalah rincian sederhana:
Ukuran penyimpanan total: Hingga 20MB per ruang kerja
Jumlah file: Hingga 100 sumber pengetahuan berbasis file per ruang kerja
Tindakan tambah/edit: Hingga 50 perubahan per hari (menambah atau mengedit sumber)
Kedalaman pemindaian: Pemindaian situs web berlangsung 3 level dalam secara default, tetapi Anda dapat meningkatkannya hingga 100 level
URL situs web tambahan: Anda dapat menambahkan hingga 5 URL tambahan per sumber pengetahuan
Jika Anda mencapai salah satu batas ini, penyinkronan dan penambahan sumber baru akan terjeda sampai ruang bebas atau batas direset.
Batasan Google Sheets
Google Sheets tidak didukung sebagai sumber pengetahuan situs web. Menambahkan URL Google Sheets dapat menyebabkan tanggapan AI yang tidak akurat atau tidak dapat diandalkan.
Apa yang dapat Anda lakukan
Unduh Google Sheet sebagai file .csv.
FAQ dan Pemecahan Masalah
Mengapa status sumber pengetahuan saya masih menunjukkan “Sedang Diproses”?
Situs web besar atau struktur tautan dalam membutuhkan waktu yang lebih lama untuk dipindai. Jika tetap tidak berubah selama berjam-jam, periksa aksesibilitas URL (robots.txt, dinding login) atau kurangi kedalaman pemindaian.
Untuk unggahan file, file yang sangat besar atau dokumen yang rusak juga dapat menyebabkan penundaan. Jika file sulit diproses, coba unggah versi yang lebih bersih dalam teks biasa atau format lain yang didukung untuk pengindeksan yang lebih cepat.
Mengapa status sumber pengetahuan saya menunjukkan “Kesalahan”?
Kesalahan biasanya terjadi karena file yang rusak, format yang tidak didukung, situs web yang diblokir, atau timeout server. Untuk memperbaiki ini, coba unggah kembali konten dalam format yang didukung (misalnya, .pdf, .docx, .csv), periksa aksesibilitas situs web, atau coba ulang pemindaian.
Bisakah saya mengunggah tautan pribadi atau internal?
Tidak, hanya URL publik yang didukung. Untuk konten pribadi, ekspor sebagai jenis file yang didukung (misalnya, PDF, TXT) dan unggah file tersebut.
Apakah AI Agent secara otomatis menggunakan semua sumber pengetahuan?
Ketika Anda membuat atau mengedit AI Agent, semua sumber pengetahuan di ruang kerja Anda akan terdaftar. Anda pilih mana yang akan diaktifkan, dan hanya sumber pengetahuan yang dipilih yang akan digunakan untuk menghasilkan balasan kepada Kontak.
Bisakah saya menggunakan Snippet sebagai sumber pengetahuan untuk AI Agents?
Tidak, Snippet tidak didukung sebagai sumber pengetahuan untuk AI Agents saat ini. Jika Anda ingin melihat fitur ini di masa depan, Anda dapat memberikan suara untuk itu di sini.
Seberapa sering saya harus menyinkronkan kembali sumber web?
Sinkronkan kembali situs yang diperbarui seringkali sesuai jadwal (misalnya, mingguan atau bulanan). Untuk konten statis, menyinkronkan ulang secara manual sudah cukup.
Bagaimana saya dapat mencegah jawaban yang usang atau tidak relevan?
Ganti atau hapus sumber yang usang, kecualikan halaman yang diarsipkan menggunakan globs, dan jadwalkan penyinkronan yang berulang untuk konten yang sering diperbarui.
Mengapa saya melihat kesalahan "Too Many Requests" saat merayapi sumber pengetahuan?
Ini bisa terjadi ketika sebuah sumber pengetahuan telah dirayapi dan dihapus lebih dari 50 kali dalam satu hari, sehingga memicu pembatasan laju. Tunggu 24 jam, lalu coba rayapi sumber pengetahuan itu lagi.
Untuk menghindari memicu pembatasan laju, hindari menambahkan, menghapus, dan menambahkan kembali sumber pengetahuan yang sama dalam waktu singkat.



