Les sources de connaissances AI aident nos fonctionnalités AI telles que les Agents AI et AI Assist à répondre avec précision en utilisant le contenu de ton entreprise—FAQ, documentation et guides d'aide. Ce guide explique comment ajouter, gérer et optimiser les sources de connaissances pour améliorer les performances des agents.
Types de fichiers et formats de liens pris en charge
Tu peux ajouter du contenu structuré et non structuré comme sources de connaissances.
Les formats pris en charge incluent :
Documents : .pdf, .txt, .md, .csv, .docx, .pptx, .ppsx
Images : .jpeg, .png, .bmp, .webp, .tiff
Liens : URL de pages web publiques
Ajout de sources de connaissances
Les sources de connaissances sont les principales données utilisées par les Agents AI et AI Assist pour générer des réponses utiles et contextuelles. Celles-ci sont indexées automatiquement et prêtes à être utilisées généralement dans quelques minutes.
Tu peux ajouter ou gérer les sources de connaissances à partir des emplacements suivants :
Agents AI > Gérer les sources de connaissances
Agents AI > Sélectionner un modèle ou commencer à partir de zéro > Ajouter des sources de connaissances
Paramètres de l'espace de travail > AI Assist > Gérer les sources de connaissances
À partir de n'importe lequel de ces emplacements, tu peux :
Télécharger des fichiers
Fais glisser et dépose plusieurs fichiers pris en charge : .pdf, .txt, .md, .csv, .docx, .pptx, .ppsx, et formats d'image (.jpeg, .png, .bmp, .webp, .tiff).
Tu peux télécharger jusqu'à 5 fichiers à la fois, avec un maximum de 100 sources de connaissances basées sur des fichiers par espace de travail.
Limites de taille de fichier : 20 Mo par fichier.
Important: Les plans d'essai ont une limite de 1 Mo par fichier, tandis que les forfaits payants autorisent jusqu'à 20 Mo par fichier.
Ajouter des URL de site web
Colle n'importe quelle URL de page web publique dans le champ URL de site web.
Par défaut, le robot d'exploration va 3 niveaux de profondeur, mais peut être ajusté jusqu'à 100 niveaux.
Tu peux ajouter jusqu'à 5 URL supplémentaires sous une seule source de connaissances de site web.
Clique sur Réactualiser pour rafraîchir le contenu ou définis un calendrier de synchronisation automatique pour le garder à jour.
Tu peux télécharger jusqu'à 3 sources de connaissances en parallèle (fichiers ou URL de site web) — pas besoin d'attendre qu'une se termine avant de commencer une autre.
Surveiller l'état
Chaque source de connaissances affiche un état :
Complétée – Prête à l'emploi
En cours – Traitement ou indexation
Erreur – Nécessite une correction (par exemple, fichier illisible, exploration bloquée)
Partiellement Complété – Certains contenus sauvegardés, mais le traitement a atteint une limite ou a expiré
Apprends-en plus sur l'utilisation des sources de connaissances avec AI Assist ici.
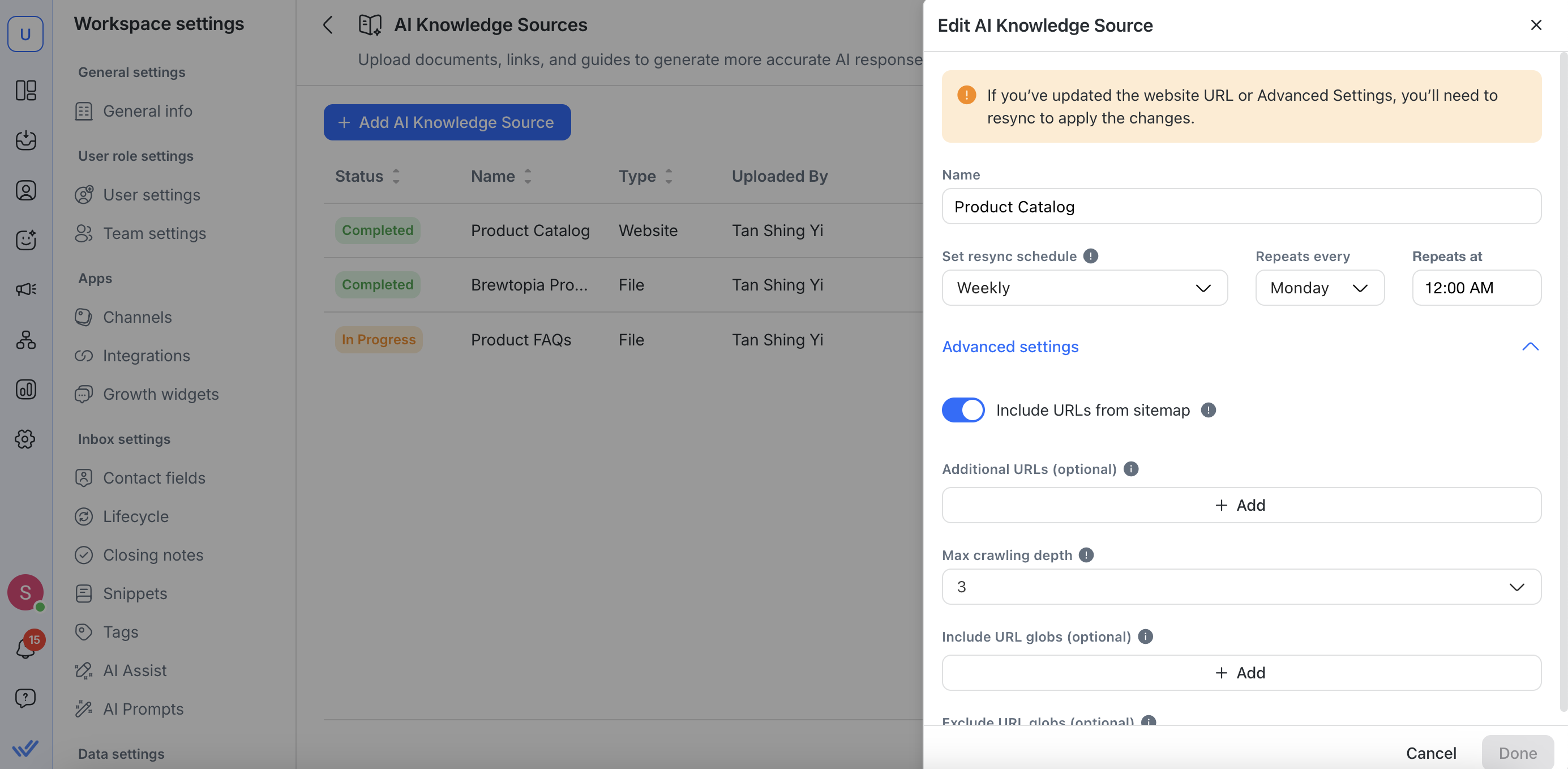
Paramètres avancés (pour les sources de connaissances de site web)
Lors de l'ajout ou de la modification d'une source de connaissances de site web, tu peux affiner le comportement d'exploration dans Paramètres avancés :
Inclure des URL de sitemap
Ceci est activé par défaut. Utilise-le si tu souhaites explorer plus d'URL, y compris des pages non liées à partir de tes URL de site web ajoutées.
Tu peux également ajouter un sitemap manuellement en tant qu'URL (par exemple, https://example.com/sitemap.xml).
Les pages des sitemaps commencent à une profondeur d'exploration de 1, et les grands sitemaps peuvent prendre plus de temps à explorer.
URL supplémentaires (optionnel) : Ajoute jusqu'à 5 points d'entrée supplémentaires.
Profondeur maximale d'exploration
Définis combien de niveaux de liens suivre. Par exemple, 0 signifie que seule l'URL fournie est explorée et 1 inclut les pages directement liées.
Des valeurs plus élevées permettent des explorations plus profondes. La profondeur d'exploration est fixée à 3 par défaut.
Inclure des globes d'URL (optionnel) :
Spécifie des modèles d'URL pour les pages que tu souhaites que le robot d'exploration inclue.
Cela s'applique uniquement aux liens trouvés sur les pages — pas aux URL de site web que tu as entrées. Pour garantir qu'une page spécifique est explorée, ajoute son URL directement sous URL de site web.
Exclure des globes d'URL (optionnel) :
Utilise cela pour exclure certaines URL de l'exploration.
Cela s'applique uniquement aux liens trouvés sur les pages — pas aux URL de site web, qui sont toujours explorées.
Qu'est-ce que des globes d'URL ?
Un globe est un modèle que tu peux utiliser pour indiquer au robot d'exploration quelles pages inclure ou sauter, sans lister chaque URL une par une.
*(astérisque simple) couvre seulement un niveau de pages.**(double astérisque) couvre tous les niveaux, y compris les sous-pages plus profondes.
Inclure des globes
Exemples corrects :
https://example.com/docs/*→ Inclut uniquement les pages directement sous/docs/(comme/docs/page1), mais pas les chemins plus profonds.https://example.com/help/**→ Inclut tout sous/help/, y compris les sous-dossiers et les pages imbriquées (comme/help/tutorials/page1).
Exemples incorrects :
https://example.com/*help*→ Ne fonctionnera pas comme prévu. Un * simple ne correspond qu'à un segment de chemin, pas à travers des dossiers.example.com/**→ Manque le protocole https://, que le robot d'exploration peut rejeter.
Exclure des globes
Exemples corrects :
https://example.com/docs/*→ Ignore uniquement les pages immédiates sous/docs/(comme/docs/page1), mais ne sautera pas celles plus profondes.https://example.com/archive/**→ Ignore tout sous/archive/, y compris les dossiers imbriqués et les sous-pages.
Autres exemples corrects :
https://example.com/**?foo=*→ Ignore toute URL surexample.comqui contient le paramètre de requêtefoo.
Exemples incorrects :
/*?foo=*→ Trop large ; pourrait ignorer inutilement des pages sur tous les domaines. Inclue toujours ton domaine (par exemple,https://example.com/**?foo=*).https://example.com/ (sans/**) → N'ignore que la page d'accueil, pas les sous-pages.
Pourquoi utiliser des globes ?
Les globes sont particulièrement utiles lorsque ton site web contient un mélange de pages utiles et non utiles pour la formation AI. Ils te donnent plus de contrôle pour :
Gagner du temps : Au lieu d'ajouter des dizaines d'URL similaires une par une, inclue-les toutes avec un seul modèle.
Réduire le bruit : Exclure des sections non pertinentes (par exemple, pages marketing, archives de blogs ou pages de connexion) afin que l'AI se concentre uniquement sur le contenu lié au support, par exemple.
Gérer des sites complexes : Pour de grands centres d'aide ou des configurations multi-domaines, les globes garantissent la couverture des sections pertinentes sans trop synchroniser de matériel non lié.
Prévenir les erreurs : En excluant des URL problématiques ou non pertinentes (comme des environnements de mise en scène ou des archives obsolètes), tu réduis les échecs d'exploration et améliores la qualité des réponses AI.
Conseils pour écrire des globes efficaces
Sois spécifique mais pas trop étroit :
https://example.com/help/**est mieux quehttps://example.com/**, qui pourrait explorer trop de contenu non pertinent.Utilise des globes d'exclusion pour un nettoyage : Si tes pages de support contiennent un contenu mixte, utilise des modèles d'exclusion (par exemple,
*/promo/**) pour filtrer le matériel marketing.Évite les globes qui se chevauchent : Les règles d'inclusion et d'exclusion se chevauchant peuvent provoquer de la confusion. Vérifie toujours les modèles pour t'assurer que tu ne passes pas involontairement des pages importantes.
Comment les agents AI utilisent les sources de connaissances
Lors de la configuration d'un agent AI—que tu commences à partir d'un modèle ou que tu en construises un à partir de zéro—tu peux connecter immédiatement des sources de connaissances pertinentes. Tu peux également les gérer plus tard en allant sur Agents AI > Gérer les sources de connaissances.
Les sources de connaissances sont utilisées pour :
Répondre avec précision aux questions sur les produits
Fournir un contenu d'aide dans le contexte
Éviter les hallucinations ou les conjectures lorsque les agents AI répondent
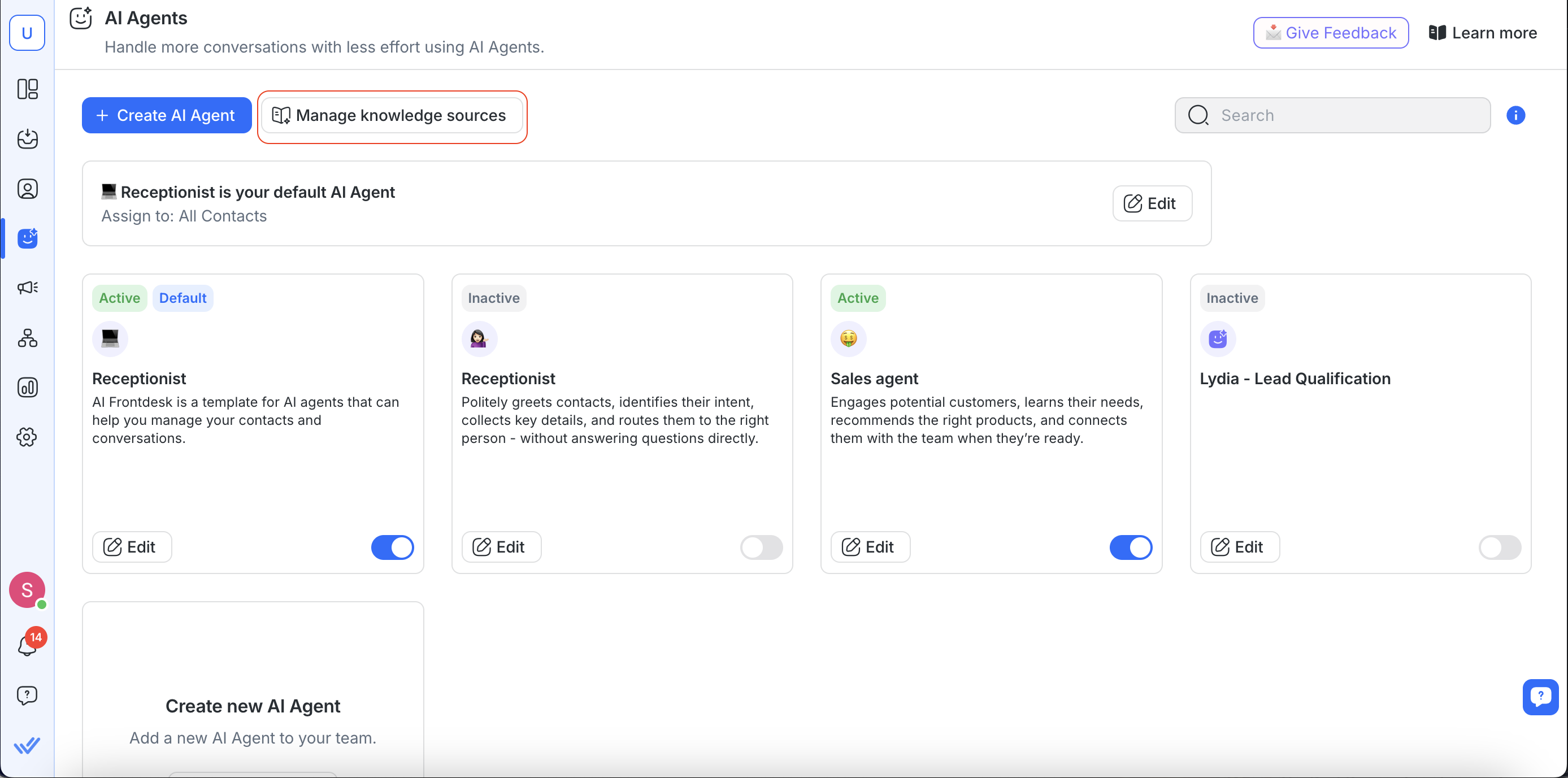
Lors de la création ou de la modification d'un agent AI :
Toutes les sources de connaissances disponibles sont listées pour que tu puisses les examiner.
Tu peux activer ou désactiver des sources de connaissances spécifiques selon l'objectif de l'agent.
Une fois activé, l'agent AI utilisera les sources de connaissances pour informer ses réponses aux contacts.
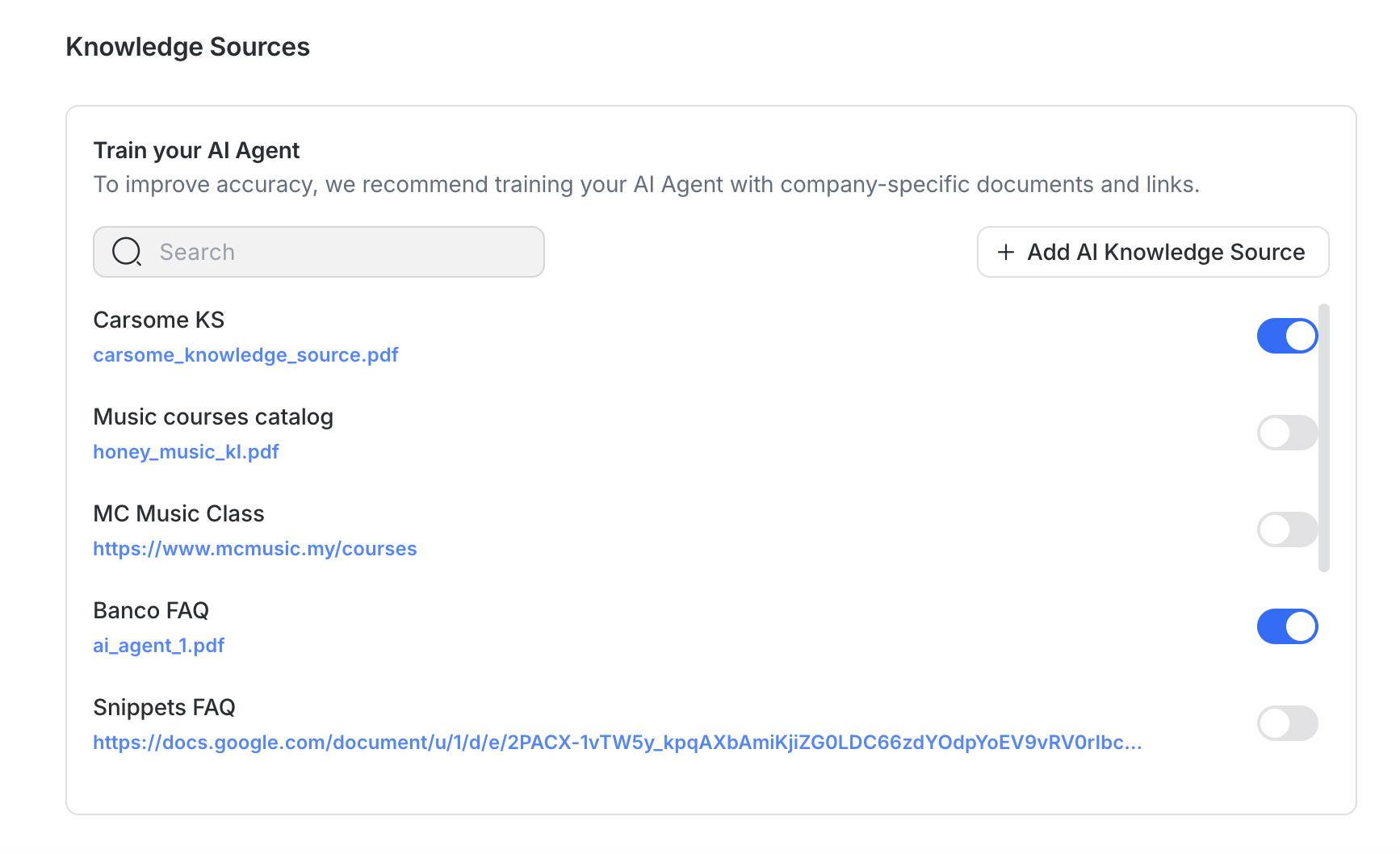
Pour améliorer la précision et la qualité des réponses :
Utilise des sources spécifiques au sujet : Évite de rassembler plusieurs sujets dans un seul fichier.
Limite le bruit : Supprime les pieds de page de marque, les mentions légales ou des infos non liées avant le téléchargement.
Lorsque tu testes un Agent IA, les réponses peuvent afficher une étiquette “{#} sources”. Cela te permet de vérifier quelles sources de connaissances ont été utilisées pour générer une réponse. Clique sur l'étiquette pour consulter les sources, ou sélectionne Gérer pour mettre à jour, resynchroniser ou remplacer directement les sources de connaissances.
Gestion des sources de connaissances existantes
Tu peux mettre à jour, remplacer, réactualiser ou supprimer des sources de connaissances via la page Sources de Connaissances AI.
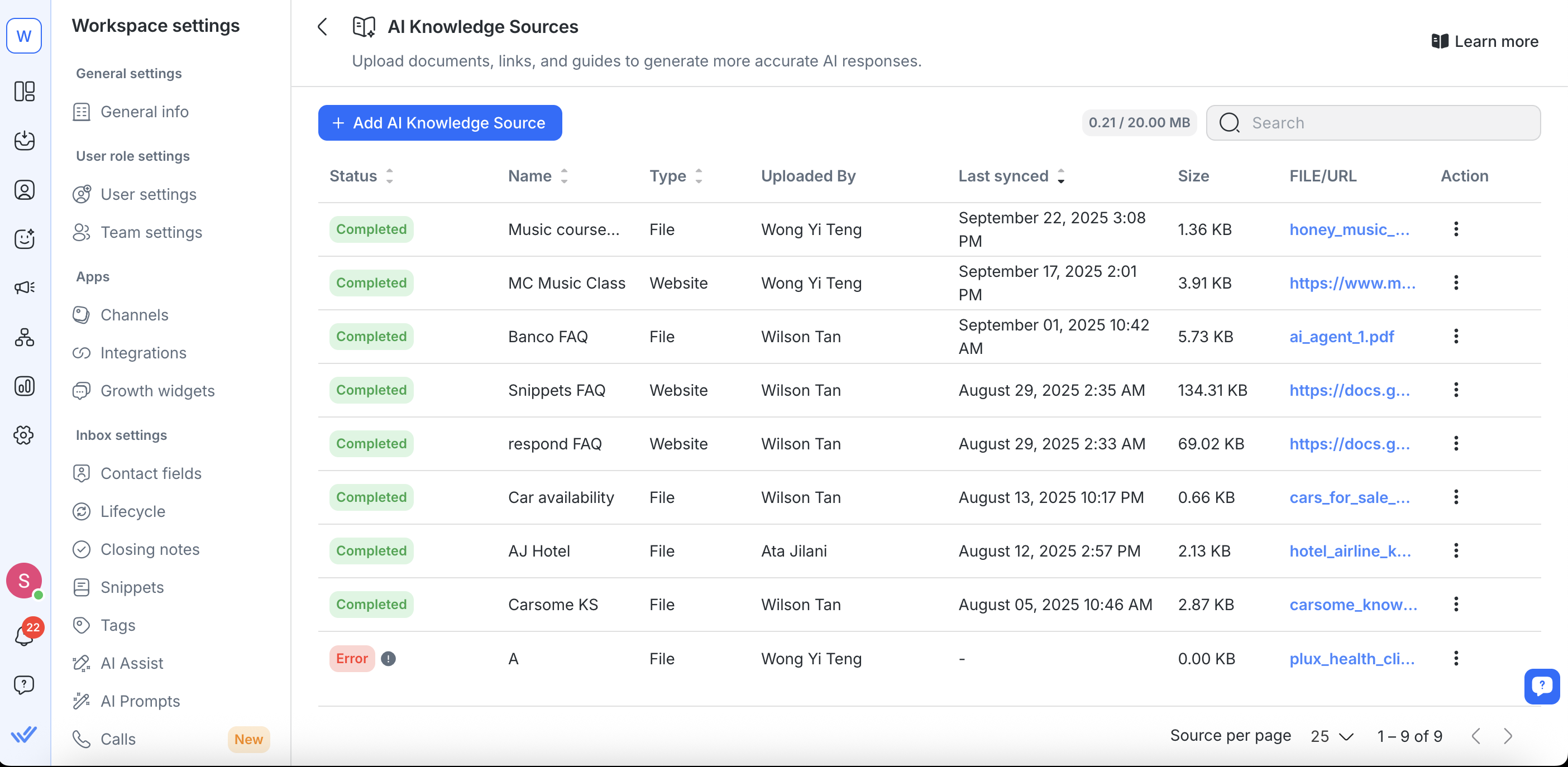
Limitations :
Les Agents IA ne peuvent pas prioriser ou sélectionner les sources de connaissance. Ils ne peuvent pas déterminer quel document est le « meilleur » ou la source la plus pertinente. Pour garantir des réponses précises, tu dois guider l'IA en lui indiquant exactement quels mots-clés rechercher dans tes sources de connaissance.
Les Agents IA ne peuvent pas rechercher par titre de document, seulement par mots-clés présents dans le contenu. Référencer un document par son nom (par ex. « consulte le Guide des tarifs ») ne fonctionnera pas. Demande plutôt à l'IA de rechercher un terme ou concept précis dans le document (par ex. « rechercher le mot-clé ‘pricing options’ »).
Modifier une source de connaissances
Pour modifier des fichiers, tu peux :
Renommer ta source de connaissances
Remplacer le fichier téléchargé (par exemple, échanger un PDF avec une version .txt)
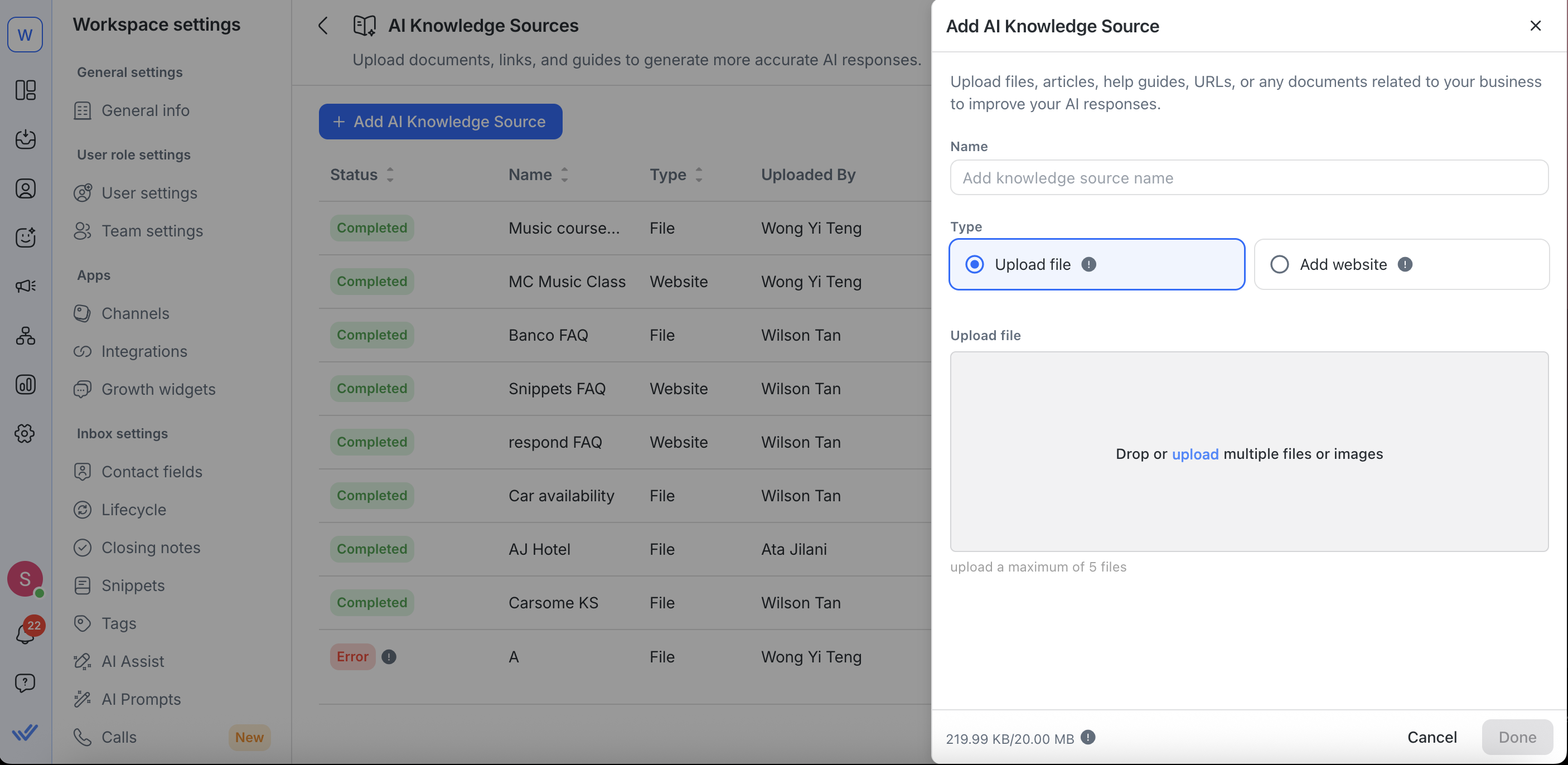
Pour modifier des URL de site web, tu peux :
Renommer ta source de connaissances
Mettre à jour ton URL de site web
Définis ou ajuste les horaires de resynchronisation
Effectue d'autres configurations dans les paramètres avancés
Si tu mets à jour l'URL du site web ou apportes des modifications dans les paramètres avancés, tu devras resynchroniser à nouveau la source de connaissances pour que les modifications prennent effet.
Supprimer une source de connaissances
Supprime les fichiers ou URLs inutilisés ou obsolètes pour respecter les limites et garder tes fonctionnalités d'IA à jour avec les informations les plus précises.
Clique sur Actions > Supprimer
Les sources de connaissances supprimées ne seront plus utilisées pour générer des réponses
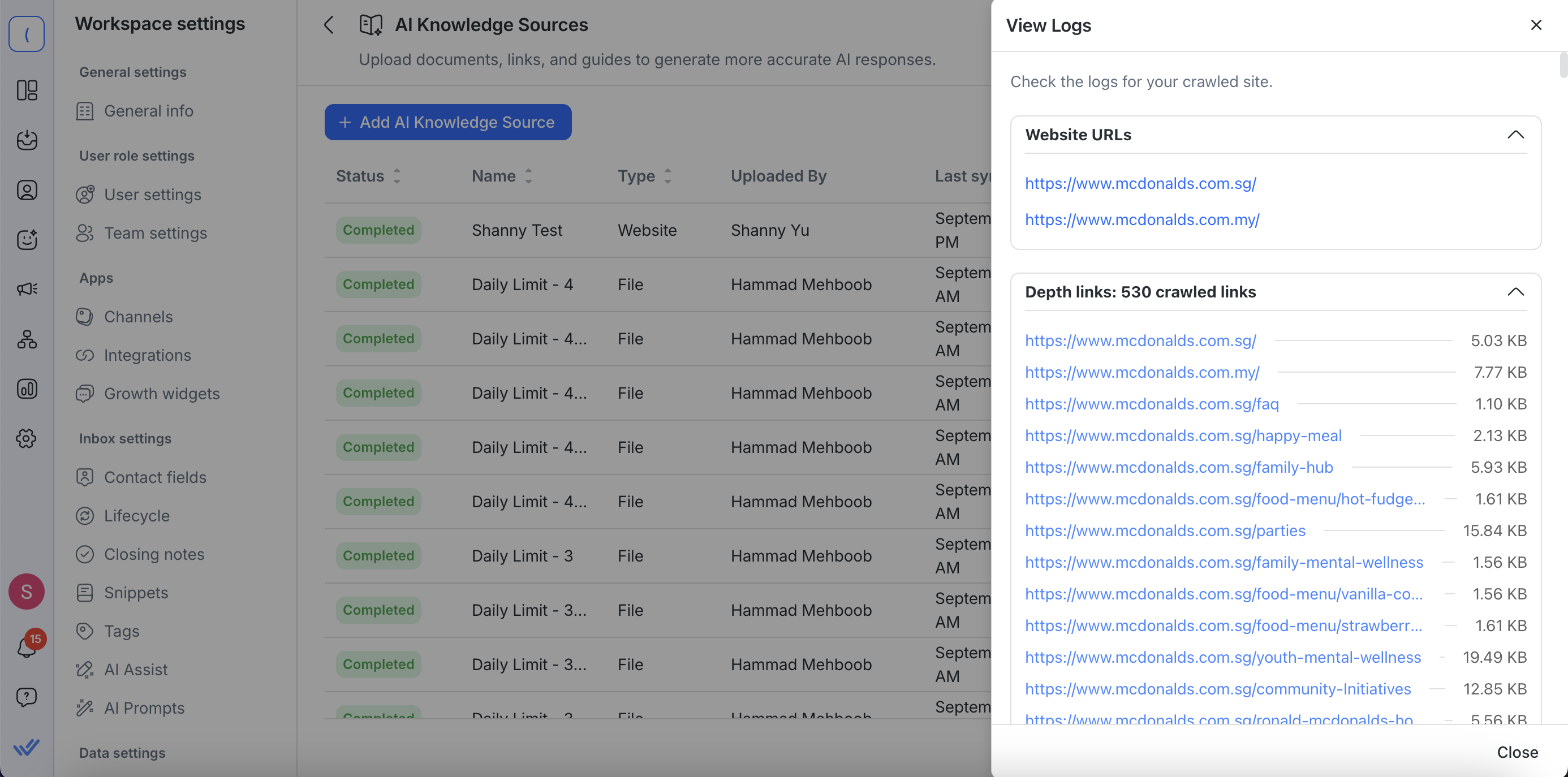
Afficher les journaux (pour les URL web)
Clique sur Actions > Afficher les journaux pour consulter les détails de l'exploration de la source de connaissances du site web. Les journaux te donnent une visibilité complète sur ce qui a été capturé :
URL de départ et additionnelles – Voir les URL de site web que tu as entrées ainsi que toute URL supplémentaire ajoutée dans les paramètres avancés.
Liste de tous les liens explorés – Chaque URL visitée est affichée.
Liens cliquables – Chaque lien exploré s'ouvre dans un nouvel onglet pour que tu puisses voir le contenu exploré directement.
Taille du contenu extrait – Vérifie la quantité de texte collectée à partir de chaque page, affichée en Ko ou Mo.
Cela facilite la confirmation que des pages importantes ont été incluses, l'identification de contenu manquant ou non pertinent, et la résolution de problèmes d'exploration.
Réactualiser les sources de site web
Pour rafraîchir le contenu web obsolète :
Clique sur Actions > Réactualiser à côté d'une source de site web
Lorsque tu cliques sur Réactualiser, le processus commence immédiatement et une icône apparaît pour montrer que c'est en cours.
Tu seras averti si la resynchronisation ne se termine pas complètement, comme par exemple :
Limite de caractères atteinte : la source sera affichée comme Partiellement terminée, et tout le contenu récupéré jusqu'à la limite est enregistré
Timeout ou erreurs de connexion : le crawl peut s'arrêter prématurément (au bout de 1 heure), le contenu partiel étant préservé lorsque c'est possible.
La resynchronisation est désactivée lorsqu'une source de connaissances est en cours de synchronisation.
Limites de l'espace de travail pour les sources de connaissances AI
Pour que tout fonctionne sans encombre, il y a des limites à combien de sources de connaissances tu peux ajouter et combien de contenu peut être stocké. Voici un aperçu simple :
Taille totale de stockage : Jusqu'à 20 Mo par espace de travail
Nombre de fichiers : Jusqu'à 100 sources de connaissances basées sur des fichiers par espace de travail
Actions d'ajout/modification : Jusqu'à 50 modifications par jour (ajout ou modification de sources)
Profondeur d'exploration : Les explorations de sites vont 3 niveaux de profondeur par défaut, mais tu peux augmenter cela jusqu'à 100 niveaux
URLs supplémentaires du site web : Tu peux ajouter jusqu'à 5 URLs supplémentaires par source de connaissances
Si tu dépasses l'une de ces limites, la synchronisation et l'ajout de nouvelles sources seront suspendus jusqu'à ce que de l'espace soit libéré ou que les limites soient réinitialisées.
Limitation de Google Sheets
Google Sheets n'est pas pris en charge comme source de connaissances pour le site web. L'ajout d'une URL Google Sheets peut entraîner des réponses de l'IA inexactes ou peu fiables.
Ce que tu peux faire
Télécharge la feuille Google Sheets en tant que fichier .csv.
FAQ et Résolution de Problèmes
Pourquoi l'état de ma source de connaissances affiche-t-il toujours "En cours" ?
Les grands sites web ou les structures de liens profonds prennent plus de temps à explorer. Si cela reste inchangé pendant des heures, vérifie l'accessibilité de l'URL (robots.txt, murs de connexion) ou réduis la profondeur d'exploration.
Pour les téléchargements de fichiers, des fichiers très volumineux ou des documents corrompus peuvent également causer des retards. Si le fichier est difficile à traiter, essaie de le télécharger à nouveau dans une version plus propre au format texte brut ou dans un autre format pris en charge pour un indexage plus rapide.
Pourquoi l'état de ma source de connaissances a-t-il affiché "Erreur" ?
Les erreurs se produisent généralement en raison de fichiers corrompus, de formats non pris en charge, de sites web bloqués ou de délais d'attente du serveur. Pour résoudre cela, essaie de télécharger à nouveau le contenu dans un format pris en charge (par exemple, .pdf, .docx, .csv), vérifie l'accessibilité du site web ou réessaie de l'exploration.
Puis-je télécharger des liens privés ou internes ?
Non, seuls les URLs publics sont pris en charge. Pour le contenu privé, exporte-le sous un type de fichier pris en charge (par exemple, PDF, TXT) et télécharge le fichier.
Les agents AI utilisent-ils automatiquement toutes les sources de connaissances ?
Lorsque tu crées ou modifies un agent AI, toutes les sources de connaissances de ton espace de travail sont listées. Tu choisis lesquelles activer, et seules les sources de connaissances sélectionnées seront utilisées pour générer des réponses aux contacts.
Puis-je utiliser des extraits comme source de connaissances pour les agents AI ?
Non, les extraits ne sont pas pris en charge comme source de connaissances pour les agents AI à ce moment. Si tu souhaites voir cette fonctionnalité à l'avenir, tu peux voter pour ici ici.
À quelle fréquence devrais-je re-synchroniser les sources de sites web ?
Resynchronise les sites fréquemment mis à jour selon un calendrier (par exemple, hebdomadairement ou mensuellement). Pour du contenu statique, des resynchronisations manuelles suffisent.
Comment puis-je éviter des réponses obsolètes ou non pertinentes ?
Remplace ou supprime les sources obsolètes, exclus les pages archivées à l'aide de globs et programme des resynchronisations récurrentes pour le contenu fréquemment mis à jour.
Pourquoi est-ce que je vois une erreur "Too Many Requests" lors de l'exploration d'une source de connaissances ?
Cela peut se produire lorsqu'une source de connaissances a été explorée et supprimée plus de 50 fois en une seule journée, entraînant une limitation du nombre de requêtes. Attends 24 heures, puis relance l'exploration de la source de connaissances.
Pour éviter d'atteindre la limite de requêtes, évite d'ajouter, de supprimer puis de réajouter la même source de connaissances en peu de temps.



