KI-Wissenquellen helfen unseren KI-Funktionen wie KI-Agenten und KI Assist, präzise auf deine Unternehmensinhalte zu reagieren – FAQs, Dokumentation und Hilfeanleitungen. Dieser Leitfaden erklärt, wie du Wissensquellen hinzufügst, verwaltest und optimierst, um die Leistung der Agenten zu verbessern.
Unterstützte Dateitypen und Linkformate
Du kannst strukturierte und unstrukturierte Inhalte als Wissensquellen hinzufügen.
Unterstützte Formate sind:
Dokumente: .pdf, .txt, .md, .csv, .docx, .pptx, .ppsx
Bilder: .jpeg, .png, .bmp, .webp, .tiff
Links: Öffentlich zugängliche Webseiten-URLs
Hinzufügen von Wissensquellen
Wissensquellen sind die Hauptdaten, die von KI-Agenten und KI Assist verwendet werden, um hilfreiche, kontextbewusste Antworten zu generieren. Diese werden automatisch indiziert und sind in der Regel innerhalb weniger Minuten einsatzbereit.
Du kannst Wissensquellen von diesen Standorten aus hinzufügen oder verwalten:
KI-Agenten > Wissensquellen verwalten
KI-Agenten > Wähle eine Vorlage oder starte von Grund auf > Wissensquellen hinzufügen
Arbeitsbereichseinstellungen > KI-Hilfe > Wissensquellen verwalten
Von jedem dieser Standorte aus kannst du:
Dateien hochladen
Ziehe mehrere unterstützte Dateien per Drag & Drop herüber: .pdf, .txt, .md, .csv, .docx, .pptx, .ppsx und Bildformate (.jpeg, .png, .bmp, .webp, .tiff).
Du kannst bis zu 5 Dateien gleichzeitig hochladen, mit maximal 100 dateibasierten Wissensquellen pro Arbeitsbereich.
Dateigrößenlimits: 20 MB pro Datei.
Wichtig: Testpläne haben eine Begrenzung von 1 MB pro Datei, während kostenpflichtige Pläne bis zu 20 MB pro Datei zulassen.
Webseiten-URLs hinzufügen
Füge eine beliebige öffentliche Webseiten-URL im Feld Webseiten-URLs ein.
Standardmäßig geht der Crawler 3 Ebenen tief, kann jedoch auf bis zu 100 Ebenen angepasst werden.
Du kannst bis zu 5 zusätzliche URLs unter einer Webseite als Wissensquelle hinzufügen.
Klicke auf Resync, um den Inhalt zu aktualisieren oder lege einen automatischen Synchronisierungszeitplan fest, um ihn aktuell zu halten.
Du kannst bis zu 3 Wissensquellen parallel hochladen (Dateien oder Webseiten-URLs) – es ist nicht erforderlich, auf das Ende eines zu warten, bevor du mit einem anderen beginnst.
Status überwachen
Jede Wissensquelle zeigt einen Status an:
Abgeschlossen – Bereit zur Nutzung
In Bearbeitung – Verarbeitet oder indiziert
Fehler – Muss behoben werden (z. B. Datei nicht lesbar, Crawlen blockiert)
Teilweise abgeschlossen – Einige Inhalte gespeichert, aber die Verarbeitung hat eine Grenze erreicht oder ist abgelaufen
Weitere Informationen zur Verwendung von Wissensquellen mit KI-Hilfe findest du hier.
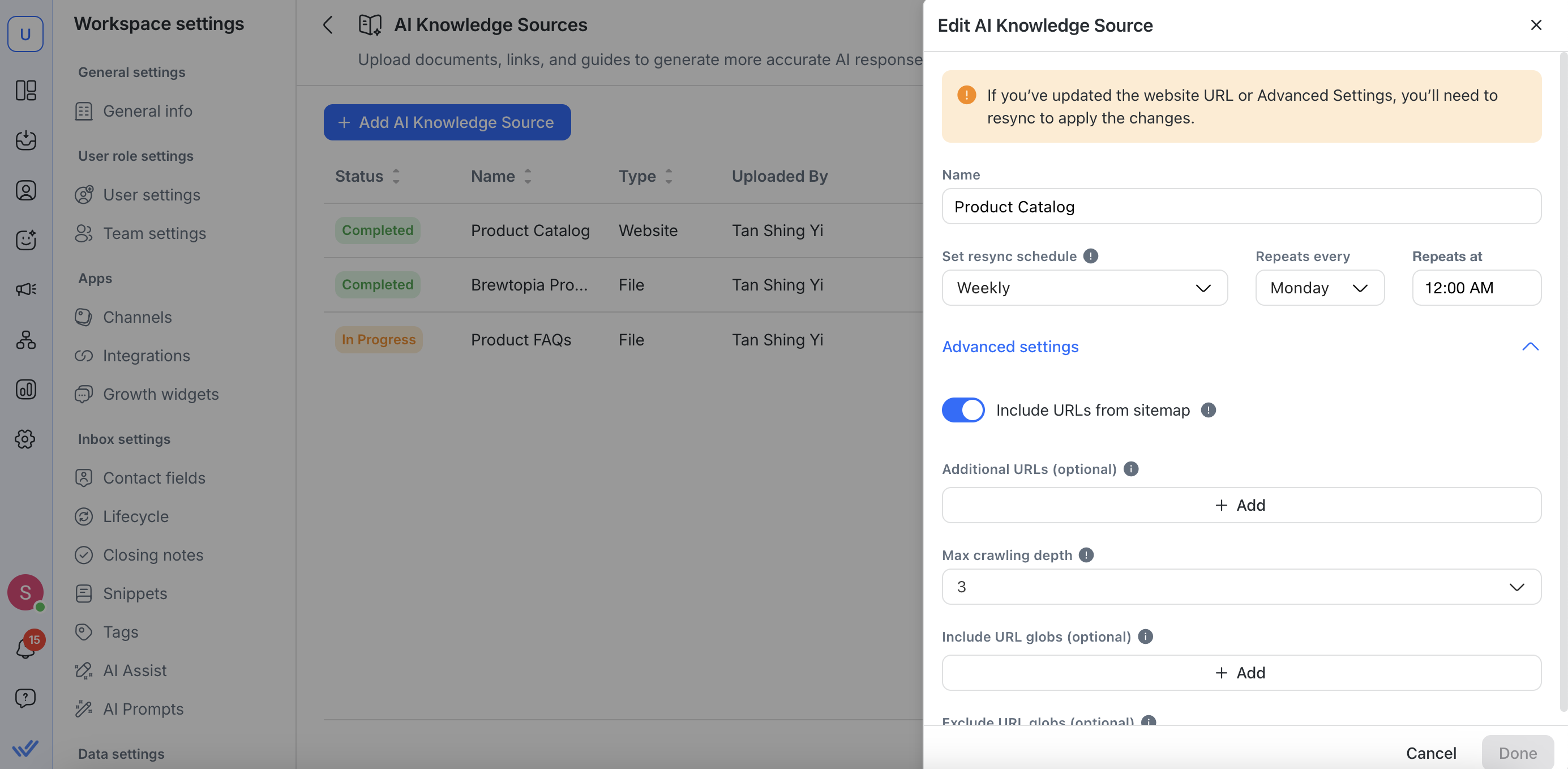
Erweiterte Einstellungen (für Webseiten-Wissensquellen)
Beim Hinzufügen oder Bearbeiten einer Webseiten-Wissensquelle kannst du das Crawlen im Erweiterten Einstellungen anpassen:
URLs aus der Sitemap einbeziehen
Das ist standardmäßig aktiviert. Verwende es, wenn du mehr URLs crawlen möchtest, einschließlich Seiten, die nicht von deinen hinzugefügten Webseiten-URLs verlinkt sind.
Du kannst auch eine Sitemap manuell als URL hinzufügen (z. B. https://example.com/sitemap.xml).
Seiten aus Sitemaps beginnen mit einer Crawltiefe von 1, und große Sitemaps können länger zum Crawlen benötigen.
Zusätzliche URLs (optional): Füge bis zu 5 weitere Einstiegspunkte hinzu.
Maximale Crawltiefe
Lege fest, wie viele Link-Ebenen verfolgt werden sollen. Zum Beispiel bedeutet 0, dass nur die bereitgestellte URL gecrawlt wird, und 1 umfasst direkt verlinkte Seiten.
Höhere Werte ermöglichen tiefere Crawls. Die Crawltiefe ist standardmäßig auf 3 eingestellt.
URLs-Globs einbeziehen (optional):
Gib URL-Muster für Seiten an, die du im Crawl enthalten möchtest.
Dies gilt nur für Links, die auf Seiten gefunden werden — nicht für die Webseiten-URLs, die du eingegeben hast. Um sicherzustellen, dass eine bestimmte Seite gecrawlt wird, füge ihre URL direkt unter Webseiten-URLs hinzu.
URLs-Globs ausschließen (optional):
Verwende dies, um bestimmte URLs vom Crawlen auszuschließen.
Dies gilt nur für Links, die auf Seiten gefunden werden — nicht die Webseiten-URLs, die immer gecrawlt werden.
Was sind URL-Globs?
Ein Glob ist ein Muster, das du verwenden kannst, um dem Crawler zu sagen, welche Seiten einzuschließen oder zu überspringen sind, ohne jede einzelne URL einzeln aufzulisten.
*(einzelner Stern) deckt nur eine Ebene von Seiten ab.**(doppelter Stern) umfasst alle Ebenen, einschließlich tiefere Unterseiten.
Globs einbeziehen
Korrekte Beispiele:
https://example.com/docs/*→ Beinhaltet nur Seiten direkt unter/docs/(wie/docs/page1), aber keine tiefer liegenden Pfade.https://example.com/help/**→ Beinhaltet alles unter/help/, einschließlich Unterordner und verschachtelte Seiten (wie/help/tutorials/page1).
Falsche Beispiele:
https://example.com/*help*→ Wird nicht wie beabsichtigt funktionieren. Einzelne * passt nur innerhalb eines Pfadsegments, nicht über Ordner hinweg.example.com/**→ Es fehlt das https://-Protokoll, das der Crawler möglicherweise ablehnt.
URLs-Globs ausschließen
Korrekte Beispiele:
https://example.com/docs/*→ Überspringt nur die unmittelbaren Seiten unter/docs/(wie/docs/page1), überspringt aber nicht tiefere.https://example.com/archive/**→ Überspringt alles unter/archive/, einschließlich verschachtelter Ordner und Unterseiten.
Andere korrekte Beispiele:
https://example.com/**?foo=*→ Überspringt jede URL aufexample.com, die den Abfrageparameterfooenthält.
Falsche Beispiele:
/*?foo=*→ Zu allgemein; könnte unbeabsichtigt Seiten über alle Domänen hinweg überspringen. Füge immer deine Domäne ein (z. B.https://example.com/**?foo=*).https://example.com/ (ohne/**) → Schließt nur die Homepage aus, nicht Unterseiten.
Warum Globs verwenden?
Globs sind besonders nützlich, wenn deine Webseite eine Mischung aus hilfreichen und weniger hilfreichen Seiten für das KI-Training enthält. Sie geben dir mehr Kontrolle, um:
Zeit zu sparen: Anstatt dutzende ähnliche URLs einzeln hinzuzufügen, kannst du sie alle mit einem einzigen Muster einbeziehen.
Geräusche reduzieren: Ausschließen irrelevanter Abschnitte (z. B. Marketingseiten, Blogarchive oder Anmeldeseiten), damit sich die KI nur auf supportbezogene Inhalte konzentriert.
Komplexe Seiten handhaben: Für große Hilfecenter oder Multi-Domain-Setups stellen Globs sicher, dass relevante Abschnitte abgedeckt werden, ohne nicht zusammenhängendes Material zu stark zu synchronisieren.
Fehler vermeiden: Durch das Ausschließen problematischer oder irrelevanter URLs (wie Staging-Umgebungen oder veralteten Archiven) reduzierst du Crawling-Fehler und verbesserst die Antwortqualität der KI.
Tipps zum Schreiben effektiver Globs
Sei spezifisch, aber nicht zu eng:
https://example.com/help/**ist besser alshttps://example.com/**, das möglicherweise zu viel irrelevanten Inhalt crawlt.Verwende Ausschluss-Globs zur Bereinigung: Wenn deine Supportseiten gemischte Inhalte enthalten, verwende Ausschlussmuster (z. B.
*/promo/**), um Marketingmaterial auszufiltern.Überlappende Globs vermeiden: Überlappende Ein- und Ausschlussregeln können zu Verwirrung führen. Überprüfe immer Muster, um sicherzustellen, dass du wichtige Seiten nicht unbeabsichtigt überspringst.
So verwenden KI-Agenten Wissensquellen
Beim Einrichten eines KI-Agenten – ob du von einer Vorlage startest oder selbst einen erstellst – kannst du sofort relevante Wissensquellen verbinden. Du kannst sie später auch verwalten, indem du zu KI-Agenten > Wissensquellen verwalten gehst.
Wissensquellen werden verwendet, um:
Produktfragen genau zu beantworten
Hilfeinhalte im Kontext bereitzustellen
Halluziationen oder Vermutungen zu vermeiden, wenn KI-Agenten antworten
Beim Erstellen oder Bearbeiten eines KI-Agenten:
Alle verfügbaren Wissensquellen sind aufgelistet, damit du sie überprüfen kannst.
Du kannst bestimmte Wissensquellen aktivieren oder deaktivieren, abhängig vom Zweck des Agenten.
Sobald aktiviert, verwendet der KI-Agent die Wissensquellen, um seine Antworten an Kontakte zu informieren.
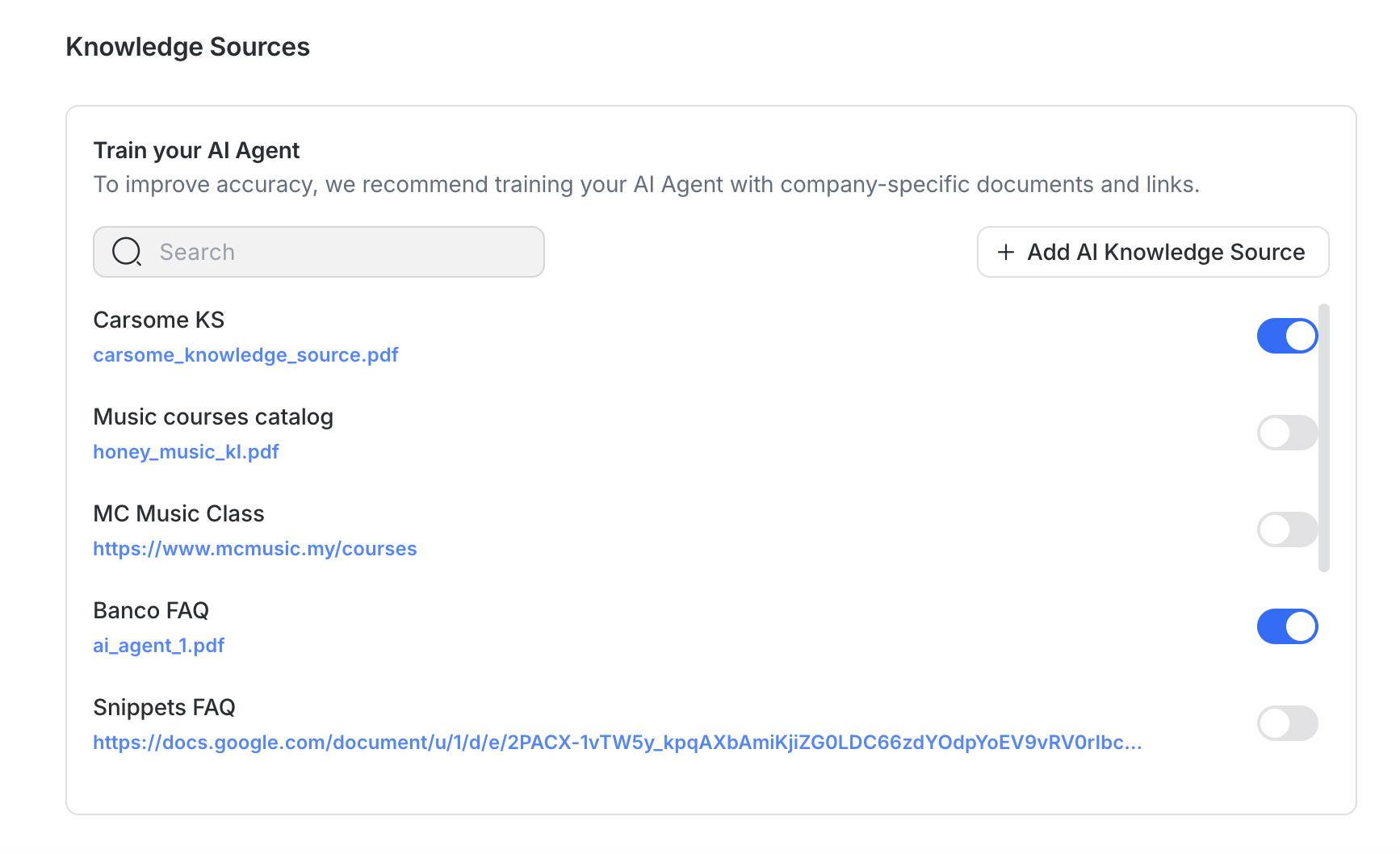
Um Genauigkeit und Antwortqualität zu verbessern:
Verwende themenspezifische Quellen: Vermeide es, viele Themen in einer Datei zusammenzufassen.
Rauschen beschränken: Entferne Branding-Fußzeilen, Haftungsausschlüsse oder nicht relevante Informationen vor dem Hochladen.
Beim Testen deines KI-Agenten kann bei Antworten das Label „{#} Quellen“ angezeigt werden. So kannst du prüfen, welche Wissensquellen zur Erstellung einer Antwort verwendet wurden. Klicke auf das Label, um die Quellen zu überprüfen, oder wähle Verwalten, um Wissensquellen direkt zu aktualisieren, neu zu synchronisieren oder zu ersetzen.
Verwalten vorhandener Wissensquellen
Du kannst Wissensquellen über die Seite KI-Wissensquellen aktualisieren, ersetzen, erneut synchronisieren oder entfernen.
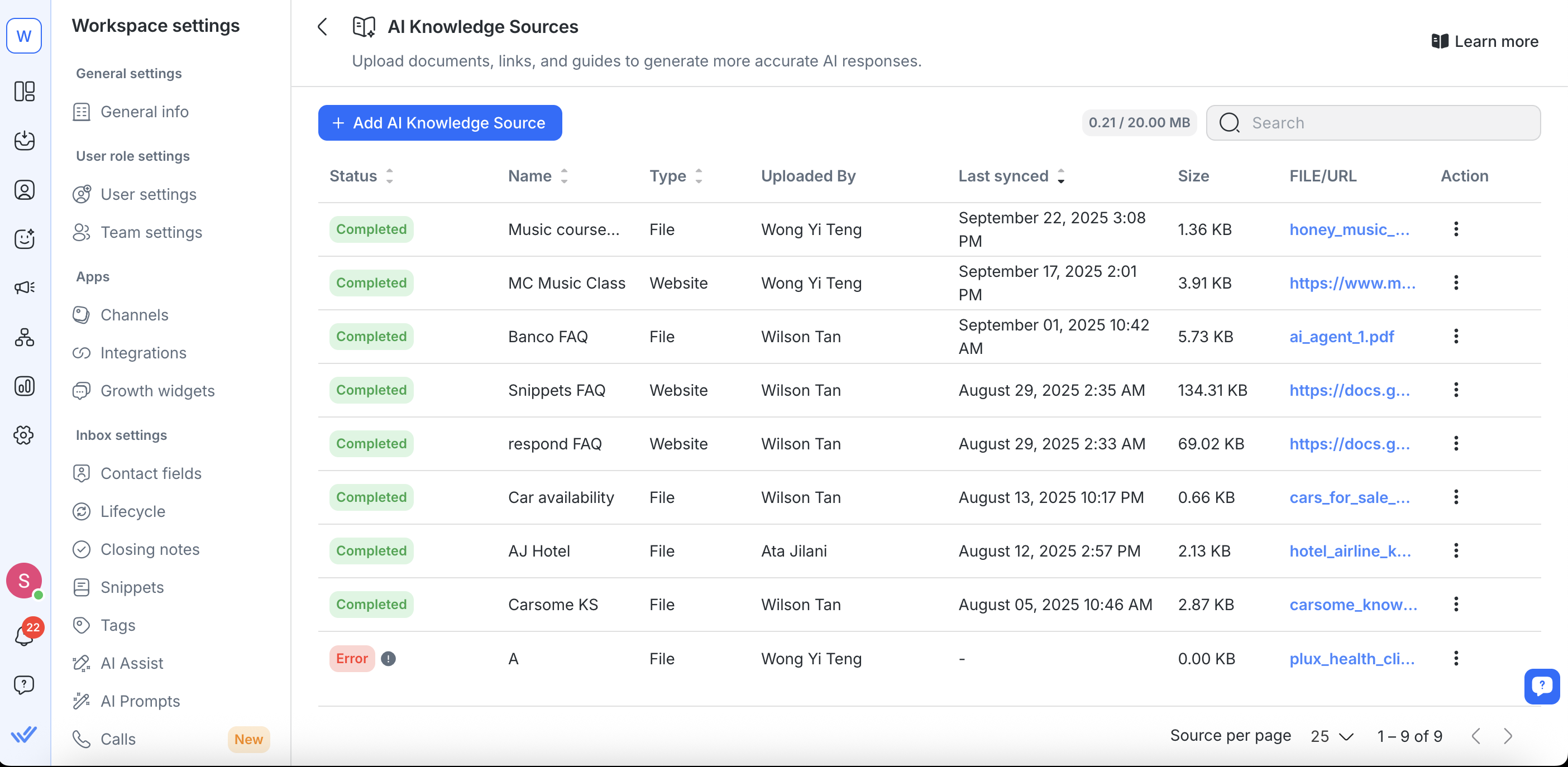
Einschränkungen:
KI‑Agenten können Wissensquellen nicht priorisieren oder auswählen. Sie können nicht bestimmen, welches Dokument die „beste“ oder relevanteste Quelle ist. Um genaue Antworten zu gewährleisten, musst du die KI anleiten, indem du ihr genau sagst, nach welchen Schlüsselwörtern sie in deinen Wissensquellen suchen soll.
KI‑Agenten können nicht nach Dokumenttiteln suchen, sondern nur nach Schlüsselwörtern im Inhalt. Das Referenzieren eines Dokuments beim Namen (z. B. „check the Pricing Guide“) funktioniert nicht. Stattdessen weise die KI an, im Dokument nach einem bestimmten Begriff oder Konzept zu suchen (z. B. „suche nach dem Schlüsselwort ‚pricing options‘“).
Eine Wissensquelle bearbeiten
Beim Bearbeiten von Dateien kannst du:
Deine Wissensquelle umbenennen
Die hochgeladene Datei ersetzen (z. B. ein PDF durch eine .txt-Version ersetzen)
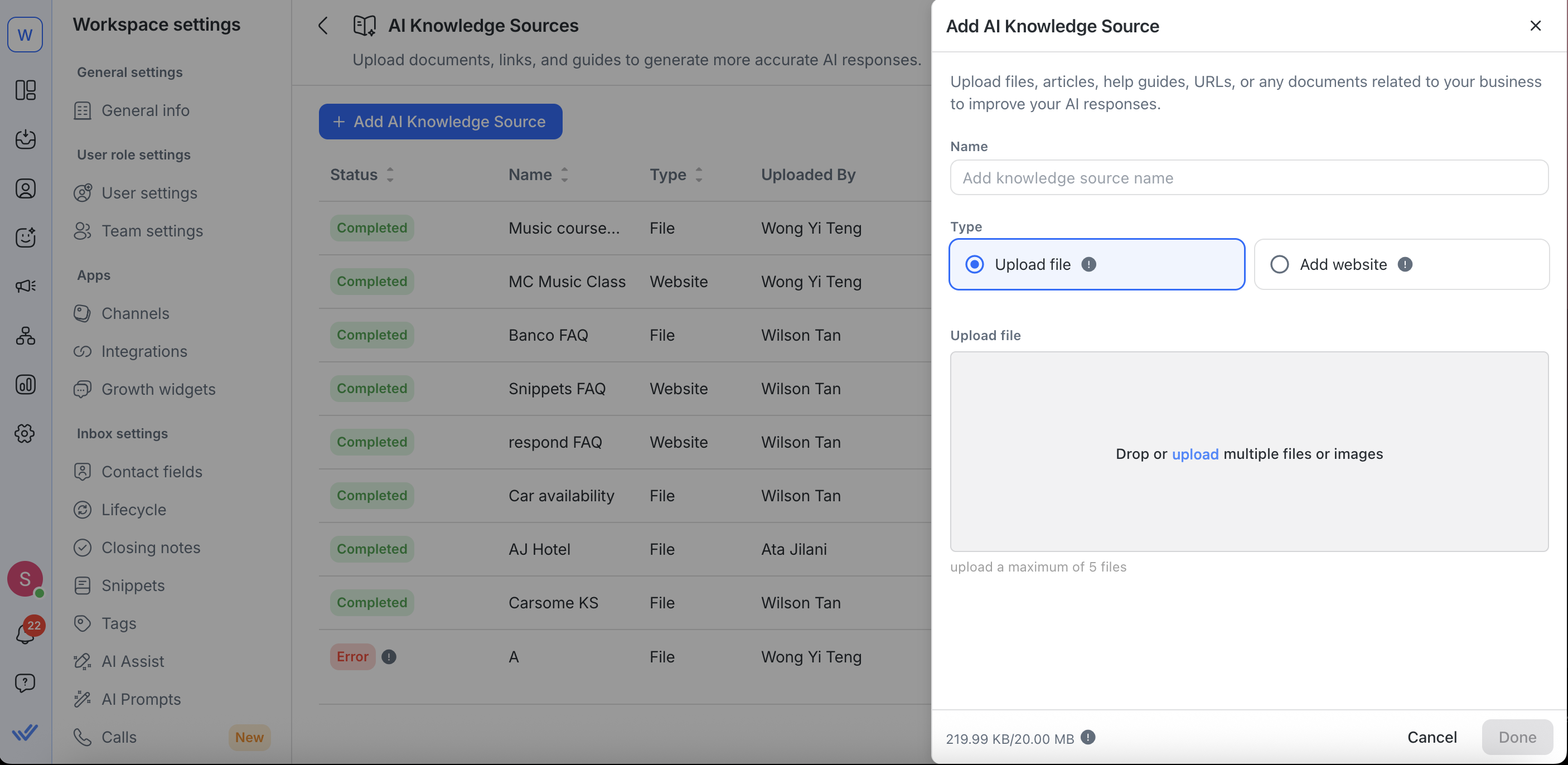
Beim Bearbeiten von Webseiten-URLs kannst du:
Deine Wissensquelle umbenennen
Deine Webseiten-URL aktualisieren
Synchronisierungszeitpläne festlegen oder anpassen
Weitere Konfigurationen in den Erweiterten Einstellungen vornehmen
Wenn du die Webseiten-URL aktualisierst oder Änderungen in den Erweiterten Einstellungen vornimmst, musst du die Wissensquelle erneut synchronisieren, damit die Änderungen wirksam werden.
Eine Wissensquelle löschen
Entferne ungenutzte oder veraltete Dateien oder URLs, um innerhalb der Limits zu bleiben und deine KI-Funktionen mit den genauesten Informationen auf dem neuesten Stand zu halten.
Klicke auf Aktionen > Löschen
Gelöschte Wissensquellen werden nicht mehr verwendet, um Antworten zu generieren
Protokolle anzeigen (für Webseiten-URLs)
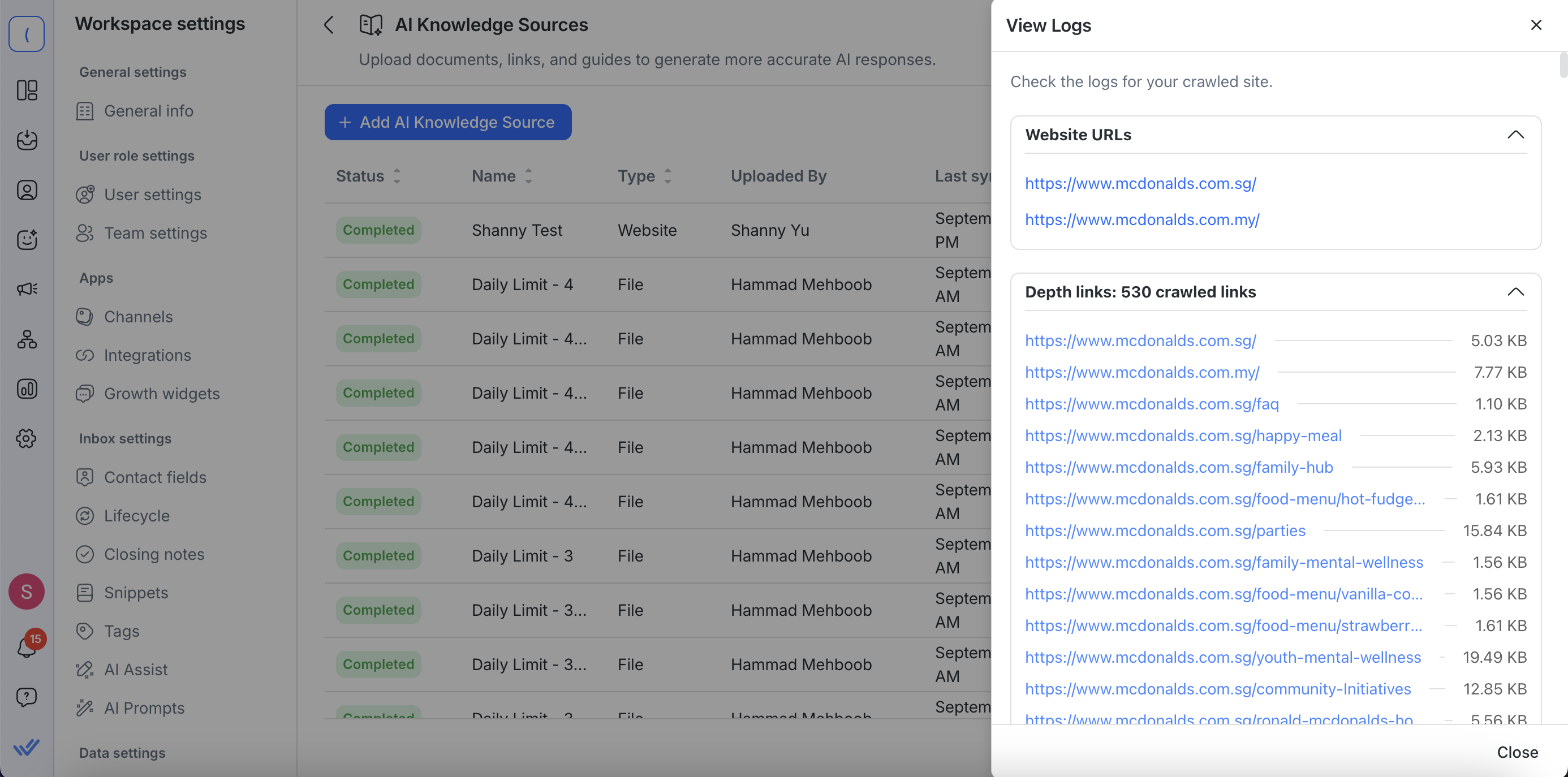
Klicke auf Aktionen > Protokolle anzeigen, um die Details eines Crawls einer Webseiten-Wissensquelle zu überprüfen. Die Protokolle geben dir volle Sichtbarkeit darüber, was erfasst wurde:
Start- und zusätzliche URLs – Sieh dir die Webseiten-URLs an, die du eingegeben hast, zusammen mit zusätzlichen URLs, die in den Erweiterten Einstellungen hinzugefügt wurden.
Liste aller gecrawlten Links – Jede besuchte URL wird angezeigt.
Klickbare Links – Jeder gecrawlte Link öffnet sich in einem neuen Tab, sodass du den gecrawlten Inhalt direkt anzeigen kannst.
Größe des extrahierten Inhalts – Überprüfe, wie viel Text von jeder Seite abgerufen wurde, angezeigt in KB oder MB.
Dies erleichtert es zu bestätigen, dass wichtige Seiten einbezogen wurden, fehlende oder irrelevante Inhalte zu identifizieren und Crawling-Probleme zu beheben.
Webseitenquellen erneut synchronisieren
Um veraltete Webinhalte zu aktualisieren:
Klicke auf Aktionen > Synchronisieren neben einer Webseitenquelle
Wenn du auf Synchronisieren klickst, startet der Prozess sofort und ein Symbol erscheint, das zeigt, dass er in Arbeit ist.
Du wirst benachrichtigt, wenn die Resynchronisierung nicht vollständig abgeschlossen wird, z. B.:
Maximale Zeichenanzahl erreicht: Die Quelle wird als Teilweise abgeschlossen angezeigt, und alle bis zur Grenze gecrawlten Inhalte werden gespeichert
Timeouts oder Verbindungsfehler: Der Crawl kann vorzeitig stoppen (nach maximal 1 Stunde), wobei Teilinhalte möglichst erhalten bleiben.
Resynchronisation ist deaktiviert, wenn eine Wissensquelle aktiv synchronisiert wird.
Grenzen für AI-Wissensquellen im Arbeitsbereich
Um einen reibungslosen Betrieb sicherzustellen, gibt es Grenzen, wie viele Wissensquellen du hinzufügen und wie viel Inhalt gespeichert werden kann. Hier ist eine einfache Übersicht:
Gesamtgröße des Speichers: Bis zu 20 MB pro Arbeitsbereich
Anzahl der Dateien: Bis zu 100 dateibasierten Wissensquellen pro Arbeitsbereich
Hinzufügen/Bearbeiten von Aktionen: Bis zu 50 Änderungen pro Tag (Hinzufügen oder Bearbeiten von Quellen)
Crawl-Tiefe: Websitecrawls gehen standardmäßig 3 Ebenen tief, können aber auf bis zu 100 Ebenen erhöht werden
Zusätzliche Website-URLs: Du kannst bis zu 5 zusätzliche URLs pro Wissensquelle hinzufügen
Wenn du eine dieser Grenzen überschreitest, wird das Synchronisieren und Hinzufügen neuer Quellen pausiert, bis Platz frei wird oder die Grenzen zurückgesetzt werden.
Einschränkung von Google Sheets
Google Sheets wird als Website-Wissensquelle nicht unterstützt. Das Hinzufügen einer Google Sheets-URL kann zu ungenauen oder unzuverlässigen KI-Antworten führen.
Was du tun kannst
Lade das Google Sheet als .csv-Datei herunter.
FAQs und Problemlösungen
Warum wird der Status meiner Wissensquelle weiterhin als “In Bearbeitung” angezeigt?
Große Websites oder tiefe Verlinkungsstrukturen benötigen länger, um gecrawlt zu werden. Wenn es stundenlang unverändert bleibt, überprüfe die URL-Zugänglichkeit (robots.txt, Login-Walls) oder reduziere die Crawl-Tiefe.
Bei Datei-Uploads können sehr große Dateien oder beschädigte Dokumente ebenfalls zu Verzögerungen führen. Wenn die Datei schwer zu verarbeiten ist, versuche, eine sauberere Version im Klartext oder im anderen unterstützten Format für ein schnelleres Indizieren erneut hochzuladen.
Warum zeigte der Status meiner Wissensquelle “Fehler” an?
Fehler treten normalerweise aufgrund von beschädigten Dateien, nicht unterstützten Formaten, blockierten Websites oder Server-Zeitüberschreitungen auf. Um dies zu beheben, versuche den Inhalt in einem unterstützten Format (z. B. .pdf, .docx, .csv) erneut hochzuladen, überprüfe die Zugänglichkeit der Website oder versuche den Crawl erneut.
Kann ich private oder interne Links hochladen?
Nein, es werden nur öffentliche URLs unterstützt. Für private Inhalte exportiere sie als unterstützten Dateityp (z. B. PDF, TXT) und lade die Datei hoch.
Verwenden AI-Agenten automatisch alle Wissensquellen?
Wenn du einen AI-Agenten erstellst oder bearbeitest, werden alle Wissensquellen in deinem Arbeitsbereich aufgelistet. Du wählst aus, welche aktiviert werden sollen, und nur diese ausgewählten Wissensquellen werden verwendet, um Antworten an Kontakte zu generieren.
Kann ich Snippets als Wissensquelle für AI-Agenten verwenden?
Nein, Snippets werden derzeit nicht als Wissensquelle für AI-Agenten unterstützt. Wenn du dieses Feature in Zukunft sehen möchtest, kannst du hier dafür abstimmen hier.
Wie oft sollte ich Wissensquellen neu synchronisieren?
Die Resynchronisation häufig aktualisierter Seiten sollte nach einem Zeitplan erfolgen (z. B. wöchentlich oder monatlich). Für statische Inhalte reichen manuelle Resynchronisationen aus.
Wie kann ich veraltete oder irrelevante Antworten verhindern?
Ersetze oder lösche veraltete Quellen, schließe archivierte Seiten durch Verwendung von Globs aus und plane regelmäßige Resynchronisationen für häufig aktualisierte Inhalte.
Warum sehe ich beim Crawlen einer Wissensquelle den Fehler "Too Many Requests"?
Das kann passieren, wenn eine Wissensquelle an einem Tag mehr als 50 Mal gecrawlt und gelöscht wurde, wodurch ein Rate-Limit ausgelöst wird. Warte 24 Stunden und versuche dann, die Wissensquelle erneut zu crawlen.
Um das Rate-Limit zu vermeiden, füge dieselbe Wissensquelle nicht kurz hintereinander wiederholt hinzu, lösche sie nicht und füge sie nicht erneut hinzu.



