Le fonti di conoscenza AI aiutano le nostre funzionalità AI come gli AI Agent e AI Assist a rispondere in modo accurato utilizzando i contenuti della tua azienda: FAQ, documentazione e guide. Questa guida spiega come aggiungere, gestire e ottimizzare le fonti di conoscenza per migliorare le prestazioni degli agenti.
Tipi di file e formati di collegamento supportati
Puoi aggiungere contenuti strutturati e non strutturati come fonti di conoscenza.
I formati supportati includono:
Documenti: .pdf, .txt, .md, .csv, .docx, .pptx, .ppsx
Immagini: .jpeg, .png, .bmp, .webp, .tiff
Collegamenti: URL di pagine web pubbliche
Aggiunta di fonti di conoscenza
Le fonti di conoscenza sono i dati principali utilizzati dagli AI Agent e AI Assist per generare risposte utili e contestualmente consapevoli. Queste vengono indicizzate automaticamente e sono solitamente pronte per l'uso entro pochi minuti.
Puoi aggiungere o gestire le fonti di conoscenza da queste posizioni:
Agenti AI > Gestisci fonti di conoscenza
Agenti AI > Seleziona un modello o inizia da zero > Aggiungi fonti di conoscenza
Impostazioni di lavoro > AI Assist > Gestisci fonti di conoscenza
Da qualsiasi di queste posizioni, puoi:
Caricare file
Trascina e rilascia più file supportati: .pdf, .txt, .md, .csv, .docx, .pptx, .ppsx e formati immagine (.jpeg, .png, .bmp, .webp, .tiff).
Puoi caricare fino a 5 file alla volta, con un massimo di 100 fonti di conoscenza basate su file per area di lavoro.
Limiti della dimensione dei file: 20MB per file.
Aggiungi URL di siti web
Incolla qualsiasi URL di pagina web pubblica nel campo URL dei siti web.
Per impostazione predefinita, il crawler va 3 livelli in profondità, ma può essere regolato fino a 100 livelli.
Puoi aggiungere fino a 5 URL aggiuntivi sotto una fonte di conoscenza del sito web.
Clicca Resync per aggiornare i contenuti o impostare un programma di sincronizzazione automatica per mantenerli aggiornati.
Puoi caricare fino a 3 fonti di conoscenza in parallelo (file o URL di siti web) — non è necessario aspettare che una finisca prima di avviarne un'altra.
Monitora lo stato
Ogni fonte di conoscenza mostra uno stato:
Completato – Pronto all'uso
In corso – Elaborazione o indicizzazione
Errore – Necessita di correzioni (ad es., file illeggibile, accesso bloccato)
Parzialmente completato – Alcuni contenuti salvati, ma l'elaborazione ha raggiunto un limite o è scaduta
Scopri di più su come utilizzare le fonti di conoscenza con AI Assist qui.
Impostazioni avanzate (per fonti di conoscenza dei siti web)
Quando aggiungi o modifichi una fonte di conoscenza del sito web, puoi regolare il comportamento di scansione in Impostazioni avanzate:
Includi URL da sitemap
Questo è abilitato per impostazione predefinita. Usalo se desideri scansionare più URL, comprese le pagine non collegate dagli URL dei siti web che hai aggiunto.
Puoi anche aggiungere un sitemap manualmente come URL (ad es., https://example.com/sitemap.xml).
Le pagine provenienti da sitemap iniziano a una profondità di scansione di 1 e sitemap di grandi dimensioni potrebbero richiedere più tempo per scansionarle.
URL aggiuntivi (opzionale): Aggiungi fino a 5 ulteriori punti di ingresso.
Profondità di scansione massima
Imposta quanti livelli di collegamento seguire. Ad esempio, 0 significa che viene scansionato solo l'URL fornito e 1 include le pagine collegate direttamente.
Valori più alti consentono scansioni più profonde. La profondità di scansione è impostata su 3 per impostazione predefinita.
Includi glob di URL (opzionale):
Specifica modelli di URL per le pagine che desideri includere nel crawler.
Questo si applica solo ai collegamenti trovati sulle pagine — non agli URL dei siti web che hai inserito. Per assicurarti che una specifica pagina venga scansionata, aggiungi il suo URL direttamente sotto URL dei siti web.
Escludi glob di URL (opzionale):
Usa questo per escludere determinati URL dalla scansione.
Questo si applica solo ai collegamenti trovati sulle pagine — non agli URL dei siti web, che vengono sempre scansionati.
Cosa sono i glob di URL?
Un glob è un modello che puoi utilizzare per indicare al crawler quali pagine includere o saltare, senza elencare ogni singolo URL uno per uno.
*(asterisco singolo) copre solo un livello di pagine.**(asterisco doppio) copre tutti i livelli, comprese le sottopagine più profonde.
Includi glob
Esempi corretti:
https://example.com/docs/*→ Include solo le pagine direttamente sotto/docs/(come/docs/page1), ma non percorsi più profondi.https://example.com/help/**→ Include tutto sotto/help/, comprese le sottocartelle e le pagine annidate (come/help/tutorials/page1).
Esempi errati:
https://example.com/*help*→ Non funzionerà come previsto. Un singolo * corrisponde solo all'interno di un segmento di percorso, non tra le cartelle.example.com/**→ Manca il protocollo https://, che il crawler potrebbe rifiutare.
Escludi glob
Esempi corretti:
https://example.com/docs/*→ Salta solo le pagine immediate sotto/docs/(come/docs/page1), ma non salta quelle più profonde.https://example.com/archive/**→ Salta tutto sotto/archive/, comprese le cartelle annidate e le sottopagine.
Altri esempi corretti:
https://example.com/**?foo=*→ Salta qualsiasi URL suexample.comche contiene il parametro di queryfoo.
Esempi errati:
/*?foo=*→ Troppo generico; potrebbe saltare involontariamente pagine su tutti i domini. Includi sempre il tuo dominio (ad esempio,https://example.com/**?foo=*).https://example.com/ (senza/**) → Esclude solo la homepage, non le sottopagine.
Perché usare i glob?
I glob sono particolarmente utili quando il tuo sito web contiene una miscela di pagine utili e non utili per la formazione dell'IA. Ti danno maggior controllo per:
Risparmiare tempo: invece di aggiungere decine di URL simili uno per uno, includili tutti con un solo modello.
Ridurre il rumore: Escludere sezioni irrilevanti (ad es., pagine di marketing, archivi di blog o pagine di accesso) affinché l'IA si concentri solo sui contenuti relativi al supporto, ad esempio.
Gestire siti complessi: per grandi centri assistenza o configurazioni multi-dominio, i glob assicurano la copertura di sezioni rilevanti senza sovrasincronizzare materiale non correlato.
Prevenire errori: escludendo URL problematici o irrilevanti (come ambienti di staging o archivi obsoleti), riduci i fallimenti di scansione e migliora la qualità delle risposte dell'IA.
Consigli per scrivere glob efficaci
Essere specifici ma non troppo ristretti:
https://example.com/help/**è meglio dihttps://example.com/**, che potrebbe scansionare troppi contenuti irrilevanti.Usa glob esclusi per la pulizia: se le tue pagine di supporto contengono contenuti misti, usa modelli esclusi (ad es.,
*/promo/**) per filtrare materiale di marketing.Evitare glob sovrapposti: regole di inclusione ed esclusione sovrapposte possono causare confusione. Controlla sempre i modelli per assicurarti di non saltare involontariamente pagine importanti.
Come utilizzano le fonti di conoscenza gli agenti AI
Quando imposti un agente AI—che tu stia partendo da un modello o costruendone uno da zero—puoi collegare immediatamente fonti di conoscenza rilevanti. Puoi anche gestirle in seguito andando su Agenti AI > Gestisci fonti di conoscenza.
Le fonti di conoscenza vengono utilizzate per:
Rispondere accuratamente a domande sui prodotti
Fornire contenuti di aiuto nel contesto
Evitare allucinazioni o congetture quando gli agenti AI rispondono
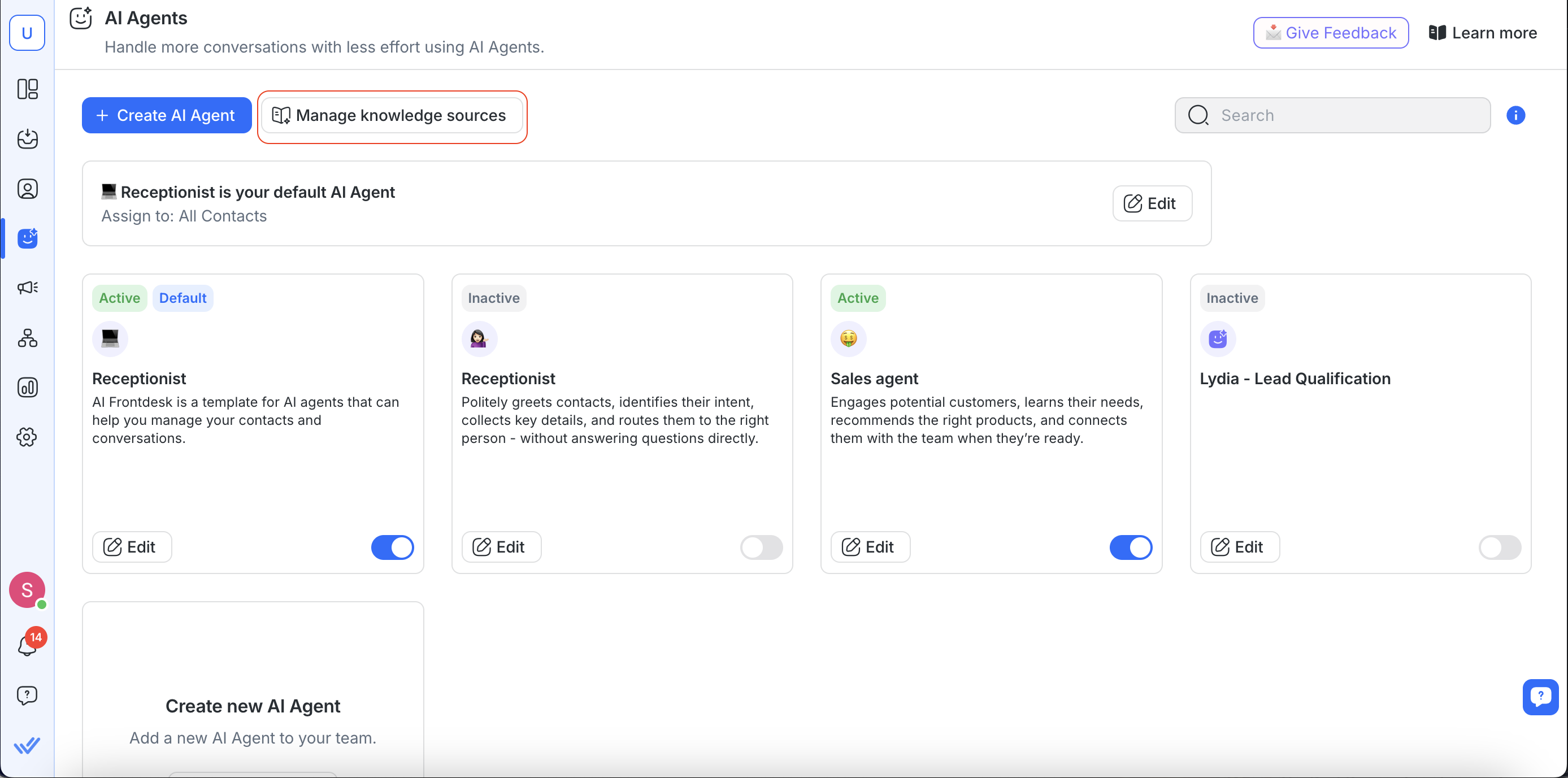
Quando crei o modifichi un agente AI:
Tutte le fonti di conoscenza disponibili sono elencate per la revisione.
Puoi abilitare o disabilitare fonti di conoscenza specifiche a seconda dello scopo dell'agente.
Una volta abilitate, l'agente AI utilizzerà le fonti di conoscenza per informare le sue risposte ai contatti.
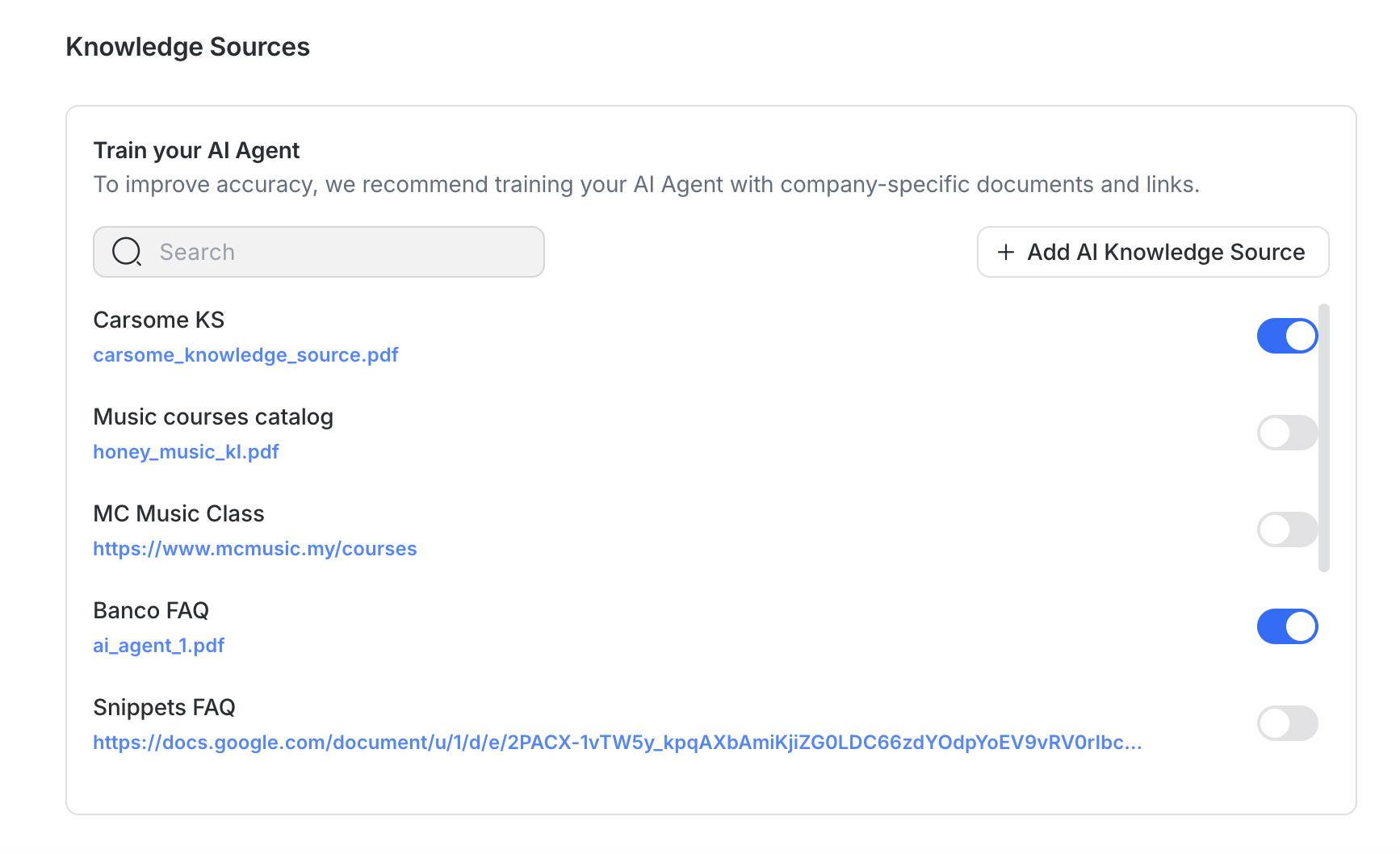
Per migliorare l'accuratezza e la qualità delle risposte:
Usa fonti specifiche per argomento: Evita di raggruppare molti argomenti in un solo file.
Limita il rumore: Rimuovi piè di pagina con il marchio, disconoscimenti o informazioni non correlate prima di caricare.
Quando testi un Agente AI, le risposte possono mostrare un'etichetta “{#} fonti”. Questo ti permette di verificare quali fonti di conoscenza sono state usate per generare una risposta. Clicca l'etichetta per visualizzare le fonti, oppure seleziona Gestisci per aggiornare, risincronizzare o sostituire direttamente le fonti di conoscenza.
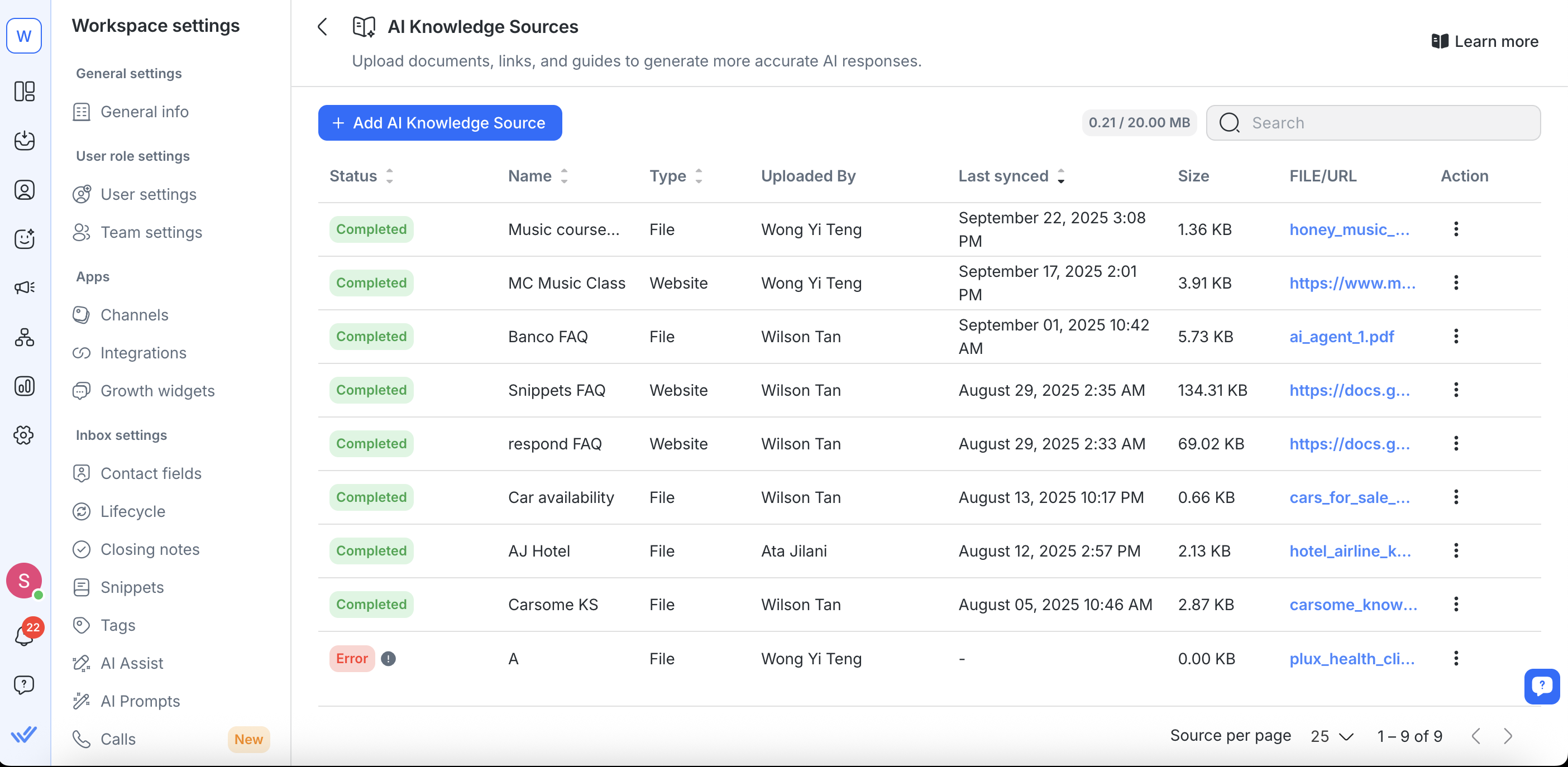
Gestione delle fonti di conoscenza esistenti
Puoi aggiornare, sostituire, risincronizzare o rimuovere fonti di conoscenza tramite la pagina Fonti di Conoscenza AI.
Limitazioni:
Gli Agenti IA non possono dare priorità o scegliere le fonti di conoscenza. Non possono determinare quale documento sia il "migliore" o la fonte più rilevante. Per garantire risposte accurate, devi guidare l'AI indicandole esattamente quali parole chiave da cercare nelle tue fonti di conoscenza.
Gli Agenti IA non possono cercare per titolo del documento, ma solo per parole chiave presenti nel contenuto. Riferirsi a un documento per nome (es. "controlla la Guida ai prezzi") non funzionerà. Invece, istruisci l'AI a cercare un termine o concetto specifico all'interno del documento (es. "cerca la parola chiave 'opzioni di prezzo'").
Modifica una fonte di conoscenza
Per modificare file, puoi:
Rinominare la tua fonte di conoscenza
Sostituire il file caricato (ad es., sostituire un PDF con una versione .txt)
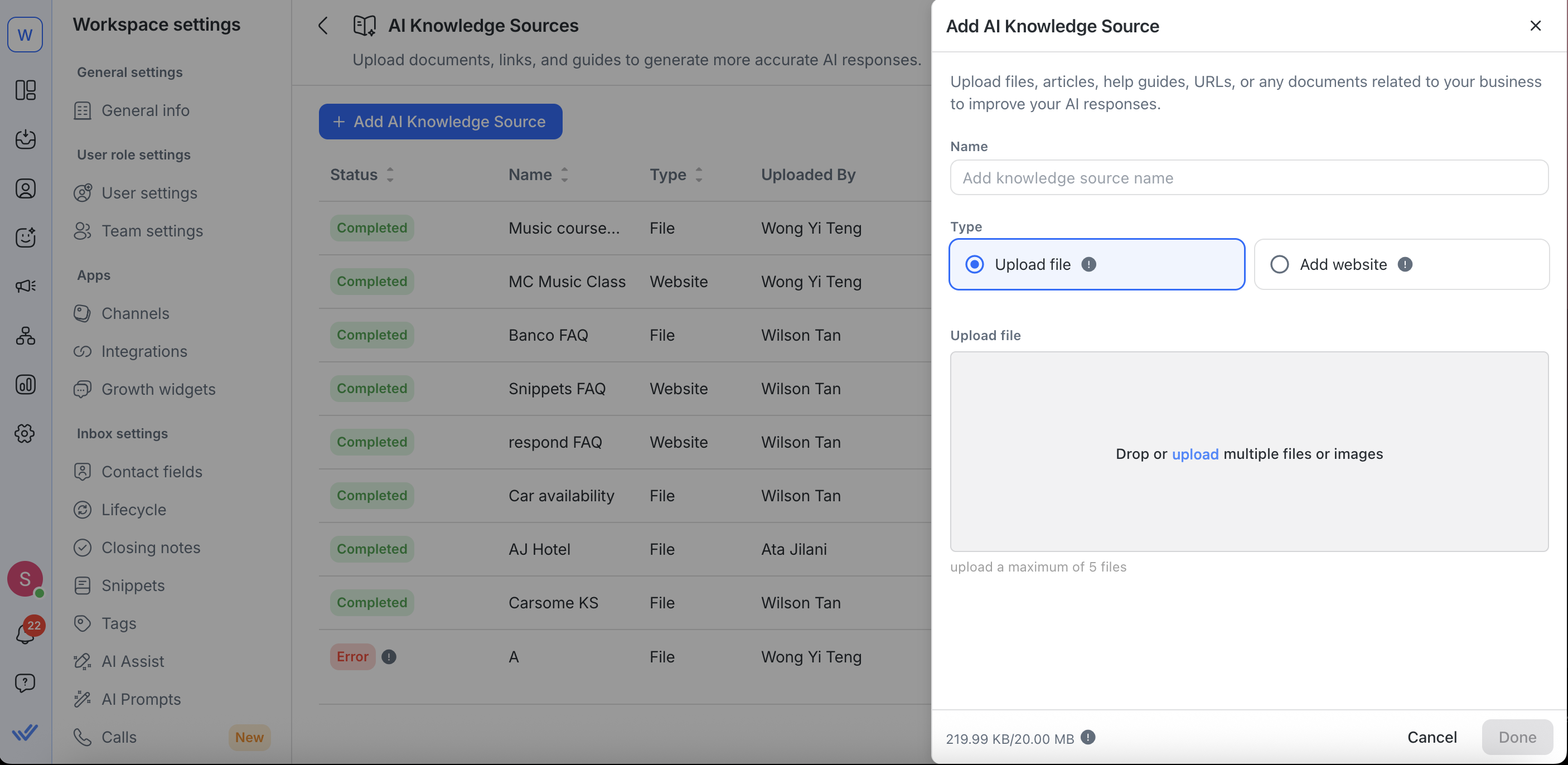
Per modificare URL di siti web, puoi:
Rinominare la tua fonte di conoscenza
Aggiornare l'URL del tuo sito web
Impostare o regolare gli orari di risincronizzazione
Apporta ulteriori configurazioni nelle impostazioni avanzate
Se aggiorni l'URL del sito web o apporti modifiche nelle impostazioni avanzate, dovrai risincronizzare la fonte di conoscenza di nuovo affinché le modifiche abbiano effetto.
Elimina una fonte di conoscenza
Rimuovi file o URL non utilizzati o obsoleti per essere entro i limiti e mantenere le tue funzionalità AI aggiornate con le informazioni più accurate.
Clicca Azioni > Elimina
Le fonti di conoscenza eliminate non verranno più utilizzate per generare risposte
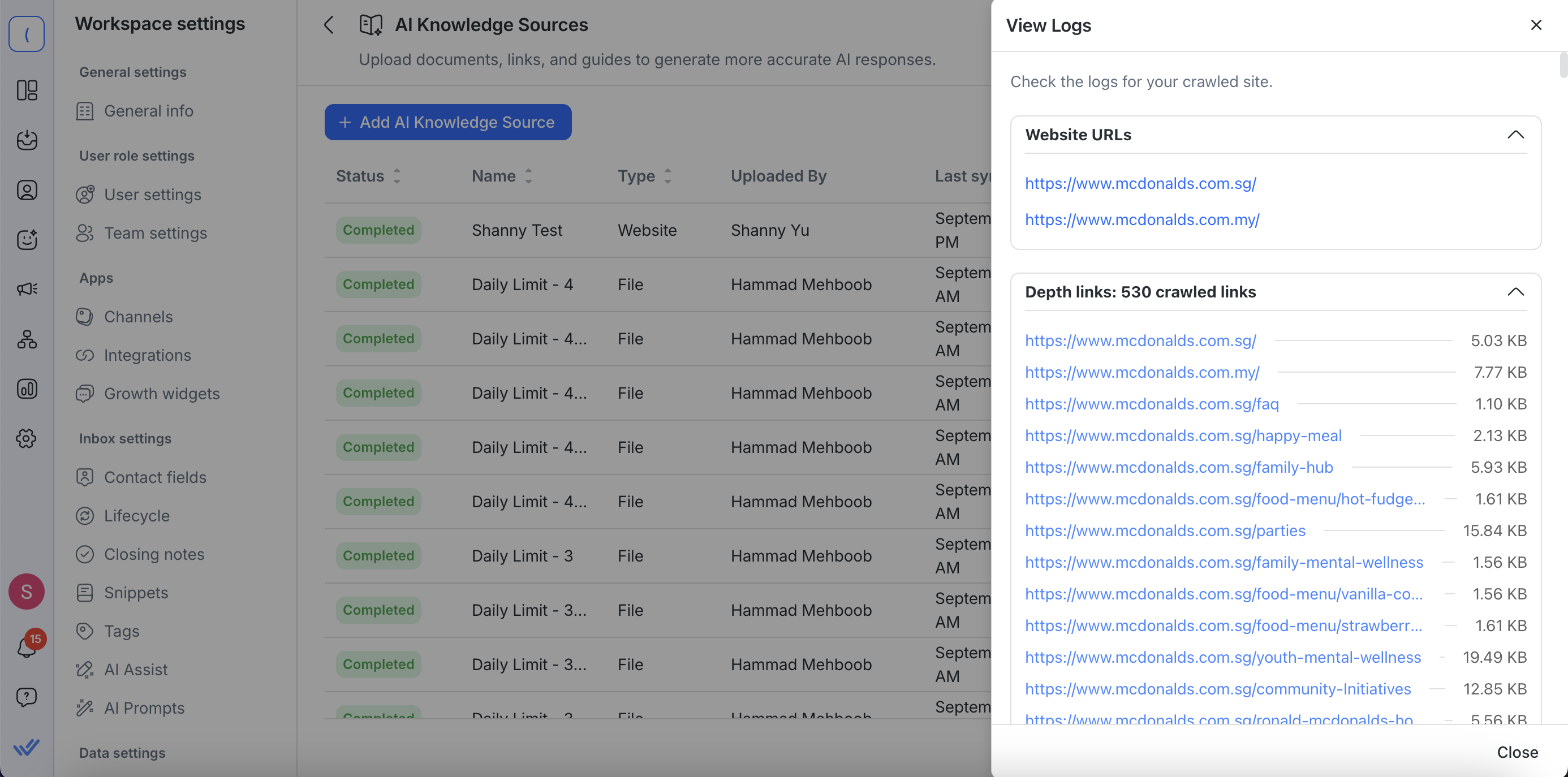
Visualizza log (per URL web)
Clicca Azioni > Visualizza log per rivedere i dettagli di una scansione della fonte di conoscenza del sito web. I log ti danno piena visibilità su ciò che è stato catturato:
URL di partenza e aggiuntivi – Vedi gli URL dei siti web che hai inserito insieme a qualsiasi URL extra aggiunto nelle impostazioni avanzate.
Elenco di tutti i collegamenti scansionati – Ogni URL visitato è mostrato.
Collegamenti cliccabili — Ogni collegamento scansionato si apre in una nuova scheda per poter visualizzare direttamente il contenuto scansionato.
Dimensione del contenuto estratto – Controlla quanto testo è stato estratto da ciascuna pagina, visualizzato in KB o MB.
Questo facilita la conferma che le pagine importanti siano state incluse, identificare contenuti mancanti o irrilevanti e risolvere eventuali problemi di scansione.
Risincronizza le fonti del sito web
Per aggiornare contenuti web obsoleti:
Clicca Azioni > Risincronizza accanto a una fonte del sito web
Quando clicchi su Risincronia, il processo inizia immediatamente e appare un'icona per mostrare che è in corso.
Verrai avvisato se la risincronizzazione non viene completata, ad esempio:
Raggiungimento del limite di caratteri: la sorgente verrà visualizzata come Parzialmente completata, e tutto il contenuto raccolto fino al limite è salvato
Timeout o errori di connessione: la scansione potrebbe interrompersi prima del previsto (dopo al massimo 1 ora), con contenuti parziali preservati dove possibile.
Il riavvio è disabilitato quando una sorgente di conoscenza è attivamente in fase di sincronizzazione.
Limiti dello spazio di lavoro per le sorgenti di conoscenza IA
Per mantenere tutto in funzione senza intoppi, ci sono limiti su quante sorgenti di conoscenza puoi aggiungere e quanto contenuto può essere memorizzato. Ecco una semplice suddivisione:
Dimensione totale di archiviazione: Fino a 20MB per spazio di lavoro
Numero di file: Fino a 100 sorgenti di conoscenza basate su file per spazio di lavoro
Aggiungi/modifica azioni: Fino a 50 modifiche al giorno (aggiunta o modifica di sorgenti)
Profondità di raccolta: Le raccolte di siti web vanno 3 livelli in profondità per impostazione predefinita, ma puoi aumentarlo fino a 100 livelli
URL extra del sito web: Puoi aggiungere fino a 5 URL aggiuntivi per sorgente di conoscenza
Se raggiungi uno di questi limiti, la sincronizzazione e l'aggiunta di nuove sorgenti si fermeranno fino a quando non verrà liberato spazio o reimpostati i limiti.
FAQ e Risoluzione problemi
Perché lo stato della mia sorgente di conoscenza mostra ancora “In corso”?
I siti web grandi o le strutture di link profondi richiedono più tempo per essere raccolti. Se rimane invariato per ore, controlla l'accessibilità dell'URL (robots.txt, login walls) o riduci la profondità di raccolta.
Per i caricamenti di file, file molto grandi o documenti corrotti possono anche causare ritardi. Se il file è difficile da elaborare, prova a ricaricare una versione più pulita in testo semplice o in un altro formato supportato per un indicizzazione più rapida.
Perché lo stato della mia sorgente di conoscenza mostra “Errore”?
Gli errori si verificano solitamente a causa di file corrotti, formati non supportati, siti web bloccati o timeout del server. Per risolvere questo problema, prova a ricaricare il contenuto in un formato supportato (ad es., .pdf, .docx, .csv), controlla l'accessibilità del sito web o ripeti la raccolta.
Posso caricare link privati o interni?
No, solo URL pubblici sono supportati. Per contenuti privati, esportalo come un tipo di file supportato (ad es., PDF, TXT) e carica il file.
Gli Agenti IA usano automaticamente tutte le sorgenti di conoscenza?
Quando crei o modifichi un Agente IA, tutte le sorgenti di conoscenza nel tuo spazio di lavoro vengono elencate. Scegli tu quali abilitare, e solo quelle sorgenti di conoscenza selezionate saranno utilizzate per generare risposte ai Contatti.
Posso usare Snippet come sorgente di conoscenza per gli Agenti IA?
No, gli Snippet non sono attualmente supportati come sorgente di conoscenza per gli Agenti IA. Se desideri vedere questa funzionalità in futuro, puoi votare qui.
Con quale frequenza dovrei ri-sincronizzare le sorgenti del sito web?
Ri-sincronizza i siti frequentemente aggiornati secondo un programma (ad es., settimanale o mensile). Per contenuti statici, le ri-sincronizzazioni manuali sono sufficienti.
Come posso prevenire risposte obsolete o irrilevanti?
Sostituisci o elimina le sorgenti obsolete, escludi le pagine archiviate usando globi e programma ri-sincronizzazioni ricorrenti per contenuti frequentemente aggiornati.



