Источники знаний ИИ помогают нашим функциям ИИ, таким как Агенты ИИ и Помощник ИИ, точно реагировать, используя ваш бизнес-контент — часто задаваемые вопросы, документацию и справочные руководства. Этот гид объясняет, как добавлять, управлять и оптимизировать источники знаний для повышения производительности агентов.
Поддерживаемые типы файлов и форматы ссылок
Вы можете добавлять структурированный и неструктурированный контент в качестве источников знаний.
Поддерживаемые форматы включают:
Документы: .pdf, .txt, .md, .csv, .docx, .pptx, .ppsx
Изображения: .jpeg, .png, .bmp, .webp, .tiff
Ссылки: URL-адреса публичных веб-страниц
Добавление источников знаний
Источники знаний являются основными данными, используемыми Агентами ИИ и Помощником ИИ для генерации полезных, контекстуально актуальных ответов. Они индексируются автоматически и обычно готовы к использованию в течение нескольких минут.
Вы можете добавлять или управлять источниками знаний из этих мест:
AI Агент > Управление источниками знаний
AI Агент > Выберите шаблон или начните с нуля > Добавить источники знаний
Настройки рабочей области > AI Assist > Управление источниками знаний
Из любого из этих мест вы можете:
Загрузить файлы
Перетащите и вставьте несколько поддерживаемых файлов: .pdf, .txt, .md, .csv, .docx, .pptx, .ppsx и форматы изображений (.jpeg, .png, .bmp, .webp, .tiff).
Вы можете загрузить до 5 файлов одновременно, с максимальным количеством 100 файловых источников знаний на одну рабочую область.
Ограничения по размеру файлов: 20 МБ на файл.
Важно: В пробных планах ограничение размера файла — 1 МБ на файл, тогда как платные планы позволяют до 20 МБ на файл.
Добавить URL-адреса веб-сайтов
Вставьте любой URL-адрес публичной веб-страницы в поле Website URLs.
По умолчанию краулер идет на 3 уровня глубже, но это можно изменить до 100 уровней.
Вы можете добавить до 5 дополнительных URL-адресов под одним источником знаний веб-сайта.
Нажмите Resync, чтобы обновить контент, или установите автоматический график синхронизации, чтобы поддерживать его в актуальном состоянии.
Вы можете загрузить до 3 источников знаний параллельно (файлы или URL веб-сайтов) — не нужно ждать завершения одного, чтобы начать другое.
Монитор статуса
Каждый источник знаний отображает статус:
Завершено – Готово к использованию
В процессе – Обработка или индексирование
Ошибка – Нуждается в исправлении (например, файл нечитаем, краул неразрешен)
Частично завершено – Некоторые данные сохранены, но обработка достигла лимита или истекло время
Узнайте больше о том, как использовать источники знаний с Помощником ИИ здесь.
Расширенные настройки (для источников знаний веб-сайтов)
При добавлении или редактировании источника знаний веб-сайта вы можете настроить поведение краулинга в Расширенных настройках:
Включить URL-адреса из карты сайта
Это включено по умолчанию. Используйте это, если хотите обойти больше URL-адресов, включая страницы, которые не связаны с вашими добавленными URL-адресами веб-сайтов.
Вы также можете вручную добавить карту сайта как URL (например, https://example.com/sitemap.xml).
Страницы из карт сайта начинают с глубины обхода 1, и большие карты сайта могут занимать больше времени для обхода.
Дополнительные URL-адреса (по желанию): Добавьте до 5 дополнительных точек входа.
Максимальная глубина обхода
Установите, сколько уровней ссылок нужно следовать. Например, 0 означает, что обходится только предоставленный URL, а 1 включает непосредственно связанные страницы.
Более высокие значения позволяют глубокий обход. Глубина обхода по умолчанию установлена на 3.
Включить URL глобусы (по желанию):
Укажите шаблоны URL для страниц, которые вы хотите, чтобы краулер включил.
Это относится только к ссылкам, найденным на страницах — не к URL-адресам веб-сайтов, которые вы ввели. Чтобы убедиться, что конкретная страница будет обойтись, добавьте ее URL непосредственно в URL-адреса веб-сайтов.
Исключить URL глобусы (по желанию):
Используйте это, чтобы исключить некоторые URL-адреса из обработки.
Это относится только к ссылкам, найденным на страницах — не к URL-адресам веб-сайтов, которые всегда обрабатываются.
Что такое URL глобусы?
Глобус — это шаблон, который вы можете использовать, чтобы сказать краулеру, какие страницы включать или пропускать, не перечисляя каждый URL по одному.
*(одинарная звездочка) охватывает только один уровень страниц.**(двойная звездочка) охватывает все уровни, включая более глубокие подпункты.
Включить паттерны
Правильные примеры:
https://example.com/docs/*→ Включает только страницы непосредственно под/docs/(например,/docs/page1), но не более глубокие пути.https://example.com/help/**→ Включает все под/help/, включая подпапки и вложенные страницы (например,/help/tutorials/page1).
Неправильные примеры:
https://example.com/*help*→ Не сработает так, как задумано. Одна * соответствует только внутри одного сегмента пути, а не через папки.example.com/**→ Отсутствует протокол https://, который краулер может отклонить.
Исключить паттерны
Правильные примеры:
https://example.com/docs/*→ Исключает только непосредственные страницы под/docs/(например,/docs/page1), но не пропускает более глубокие.https://example.com/archive/**→ Исключает все под/archive/, включая вложенные папки и подпункты.
Другие правильные примеры:
https://example.com/**?foo=*→ Исключает любой URL наexample.com, который содержит параметр запросаfoo.
Неправильные примеры:
/*?foo=*→ Слишком общий; может непреднамеренно пропустить страницы по всем доменам. Всегда включайте ваш домен (например,https://example.com/**?foo=*).https://example.com/ (без/**) → Исключает только домашнюю страницу, не пропуская подстраницы.
Почему использовать глобусы?
Паттерны особенно полезны, когда на вашем сайте есть смесь полезных и бесполезных страниц для обучения ИИ. Они дают вам больше контроля для того, чтобы:
Экономить время: Вместо того чтобы добавлять десятки похожих URL один за другим, включите их все с помощью одного шаблона.
Снизить шум: Исключить нерелевантные разделы (например, маркетинговые страницы, архивы блогов или страницы входа), чтобы ИИ сосредоточился только на контенте, связанном с поддержкой.
Управлять сложными сайтами: Для больших справочных центров или многодоменных настроек глобусы обеспечивают охват релевантных разделов без чрезмерной синхронизации нерелевантного материала.
Предотвратить ошибки: Исключив проблемные или нерелевантные URL-адреса (например, тестовые среды или устаревшие архивы), вы снижаете количество ошибок при обходе и повышаете качество ответов AI.
Советы по написанию эффективных глобусов
Будьте конкретными, но не слишком узкими:
https://example.com/help/**лучше, чемhttps://example.com/**, который может сканировать слишком много нерелевантного контента.Используйте исключения глобусов для очистки: Если ваши страницы поддержки содержат смешанный контент, используйте шаблоны исключений (например,
*/promo/**), чтобы отфильтровать маркетинговые материалы.Избегайте перекрывающихся глобусов: Перекрывающиеся включения и исключения могут вызвать путаницу. Всегда дважды проверяйте шаблоны, чтобы убедиться, что вы непреднамеренно не пропускаете важные страницы.
Как AI Агенты используют источники знаний
При настройке AI Агент — будь вы начинающим с шаблона или создающим его с нуля — вы можете сразу подключить соответствующие источники знаний. Вы также можете управлять ими позже, перейдя к AI Агентам > Управление источниками знаний.
Источники знаний используются для:
Точного ответа на вопросы о продукте
Предоставьте справочный контент в контексте
Избегайте галлюцинаций и догадок, когда Агенты ИИ отвечают
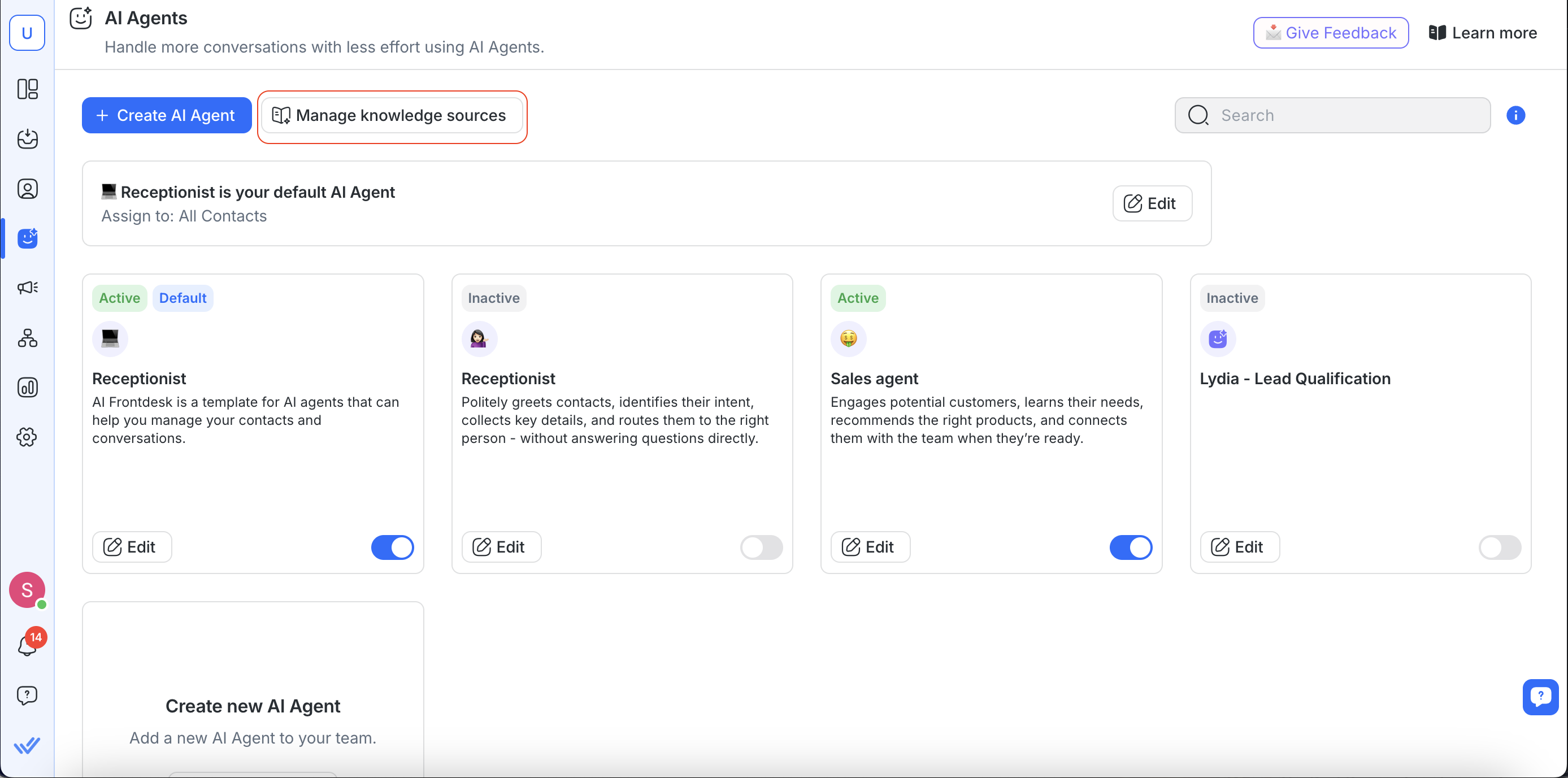
При создании или редактировании Агента ИИ:
Все доступные источники знаний перечислены для проверки
Вы можете включить или отключить отдельные источники знаний в зависимости от цели агента.
После включения Агент ИИ будет использовать источники знаний для формирования ответов контактам.
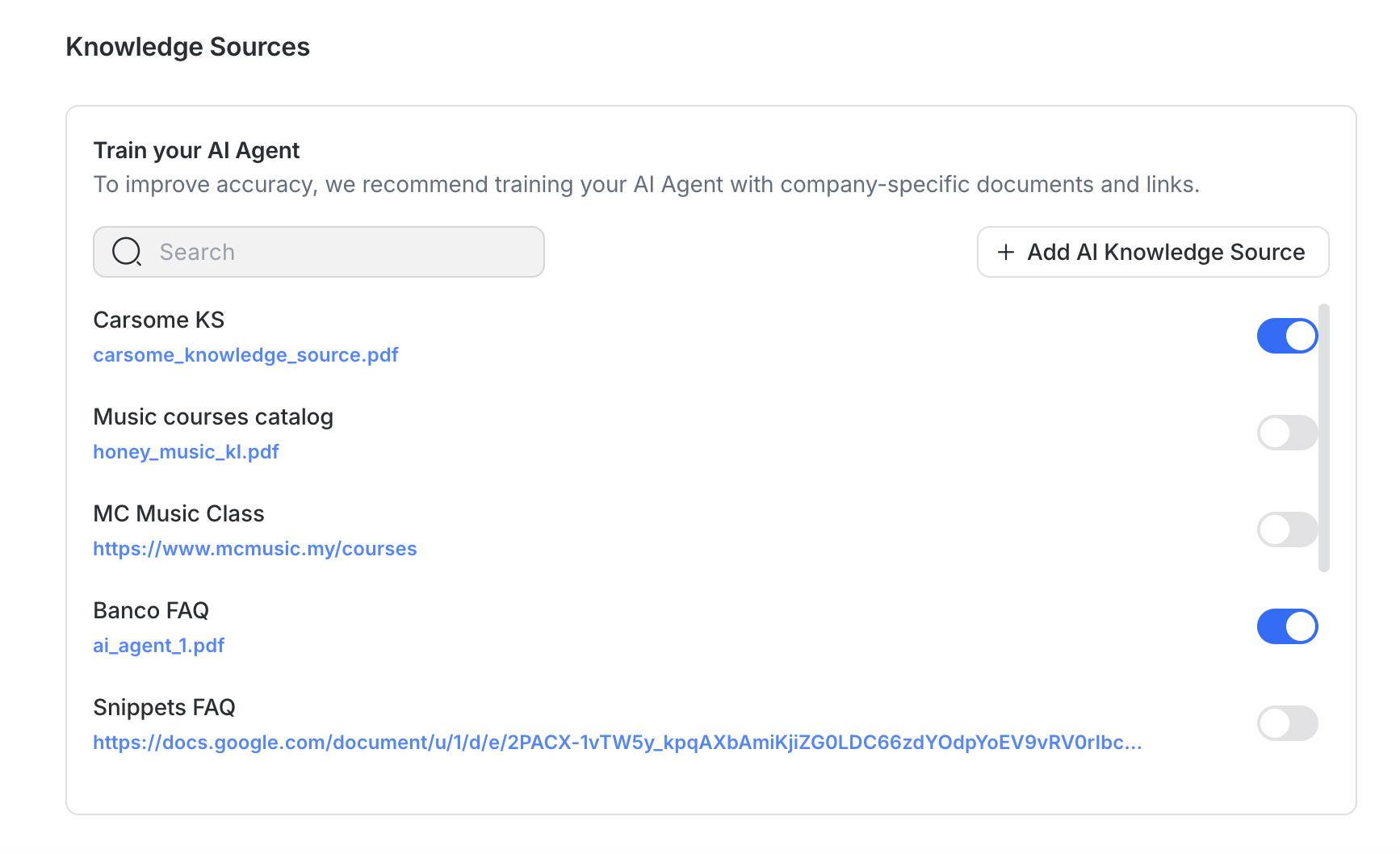
Чтобы повысить точность и качество ответов:
Используйте источники, специфичные для темы: Избегайте объединения множества тем в один файл.
Снизьте шум: Удалите брендинг, оговорки или нерелевантную информацию перед загрузкой.
При тестировании Агента ИИ ответы могут отображать метку «{#} источников». Это позволяет тебе проверить, какие источники знаний были использованы для генерации ответа. Нажми на метку, чтобы просмотреть источники, или выбери Управление, чтобы напрямую обновить, повторно синхронизировать или заменить источники знаний.
Управление существующими источниками знаний
Вы можете обновлять, заменять, ресинхронизировать или удалять источники знаний на странице Источники знаний AI.
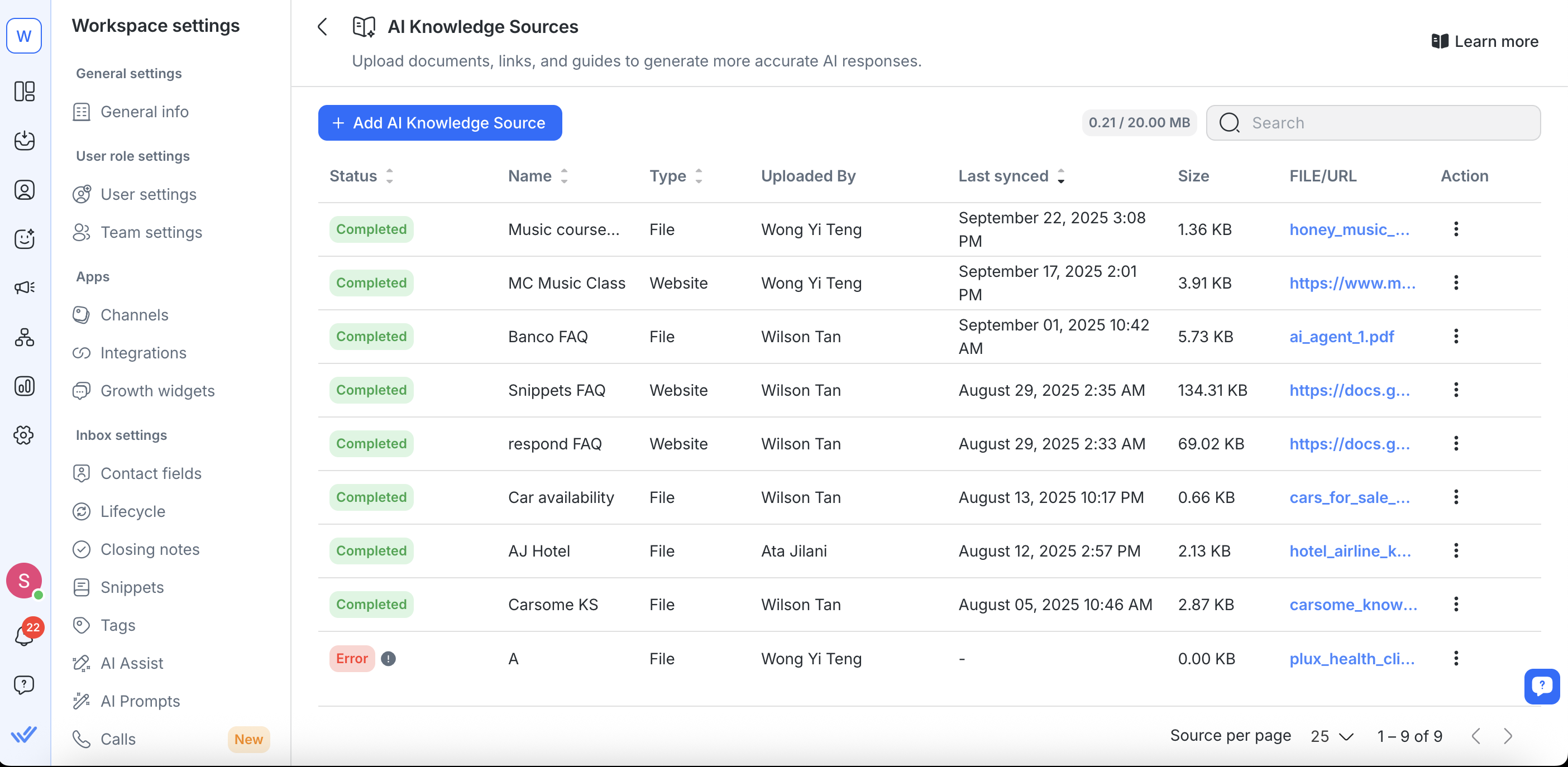
Ограничения:
Агенты ИИ не могут расставлять приоритеты или выбирать источники знаний. Они не могут определить, какой документ является «лучшим» или наиболее релевантным источником. Чтобы обеспечить точные ответы, ты должен направлять Агента ИИ, точно указывая, какие ключевые слова искать в твоих источниках знаний.
Агенты ИИ не могут искать по названию документа, только по ключевым словам внутри содержимого. Обращение к документу по имени (например, «check the Pricing Guide») не сработает. Вместо этого инструктируй Агента ИИ искать конкретный термин или понятие внутри документа (например, «search for the keyword ‘pricing options’»).
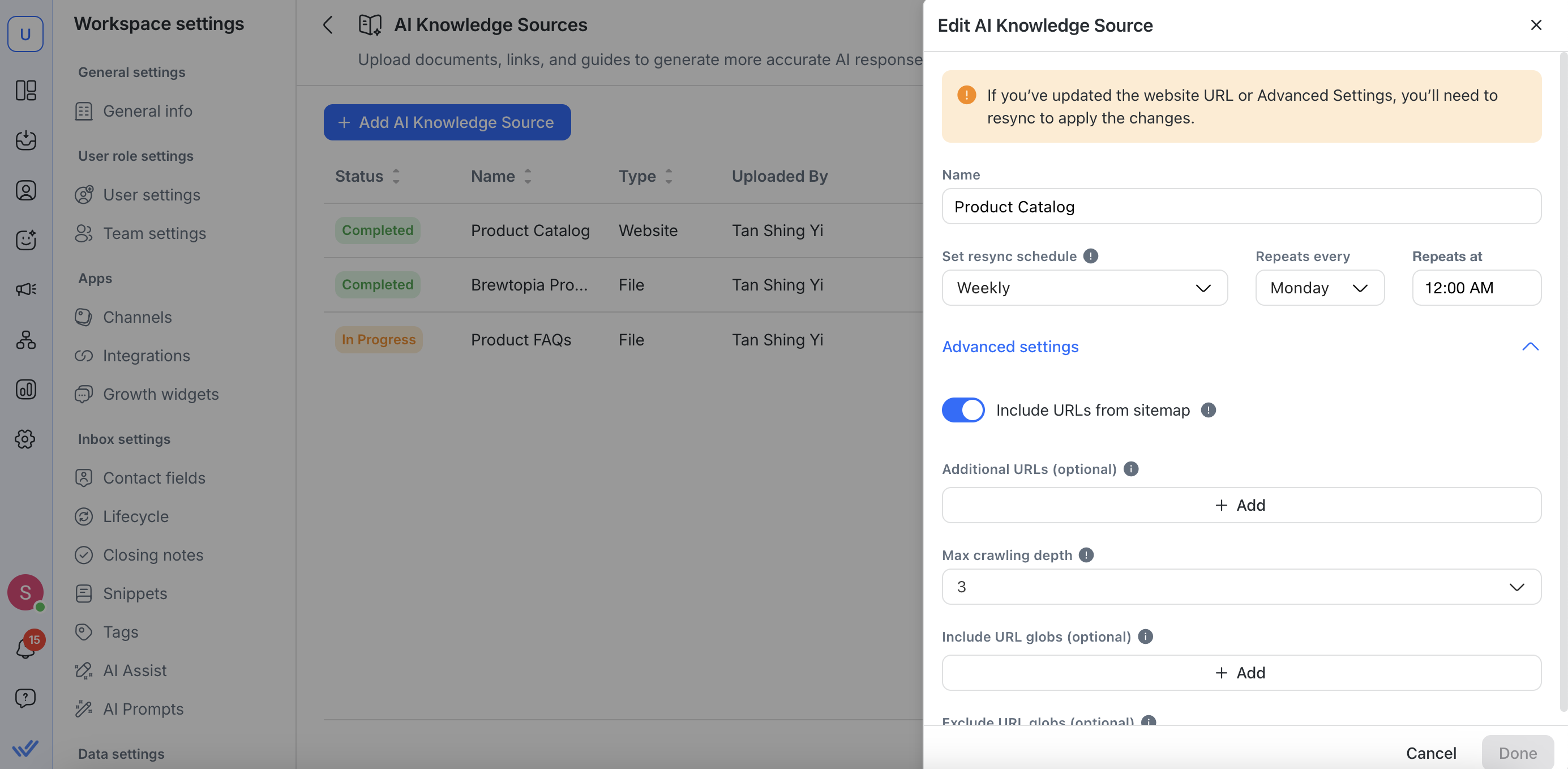
Редактировать источник знаний
Для редактирования файлов вы можете:
Переименовать ваш источник знаний
Заменить загруженный файл (например, заменить PDF версию на .txt)
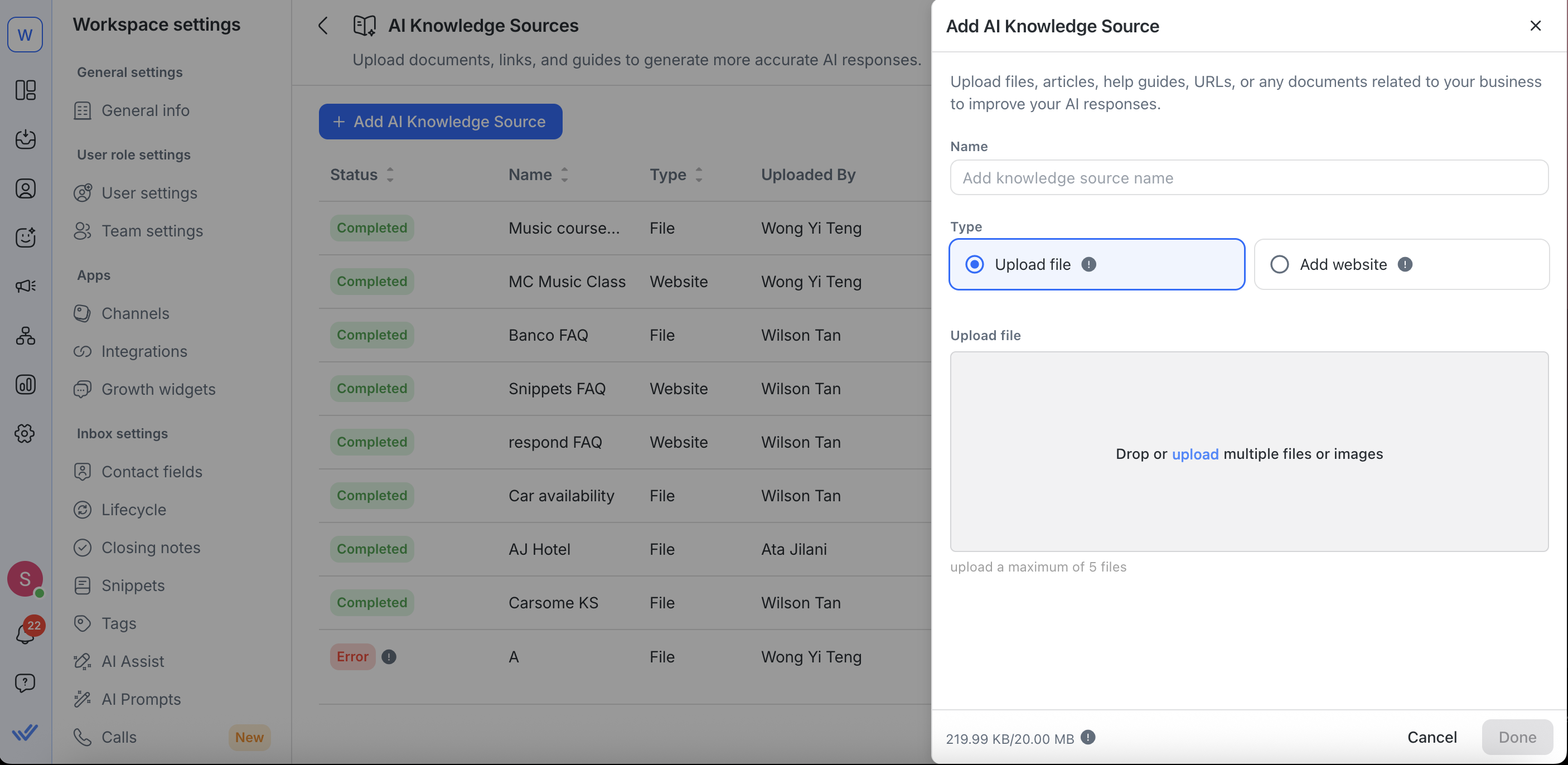
Для редактирования URL-адресов веб-сайтов вы можете:
Переименуйте ваш источник знаний
Обновите URL сайта
Установите или настройте расписания ресинхронизации
Выполните дополнительные настройки в разделе «Расширенные настройки»
Если вы обновите URL-адрес веб-сайта или внесете изменения в Расширенные настройки, вам нужно будет снова ресинхронизировать источник знаний, чтобы изменения вступили в силу.
Удалить источник знаний
Удалите неиспользуемые или устаревшие файлы или URL, чтобы оставаться в рамках лимитов и поддерживать ваши функции AI в актуальном состоянии с самой точной информацией.
Нажмите Действия > Удалить
Удаленные источники знаний больше не будут использоваться для генерации ответов
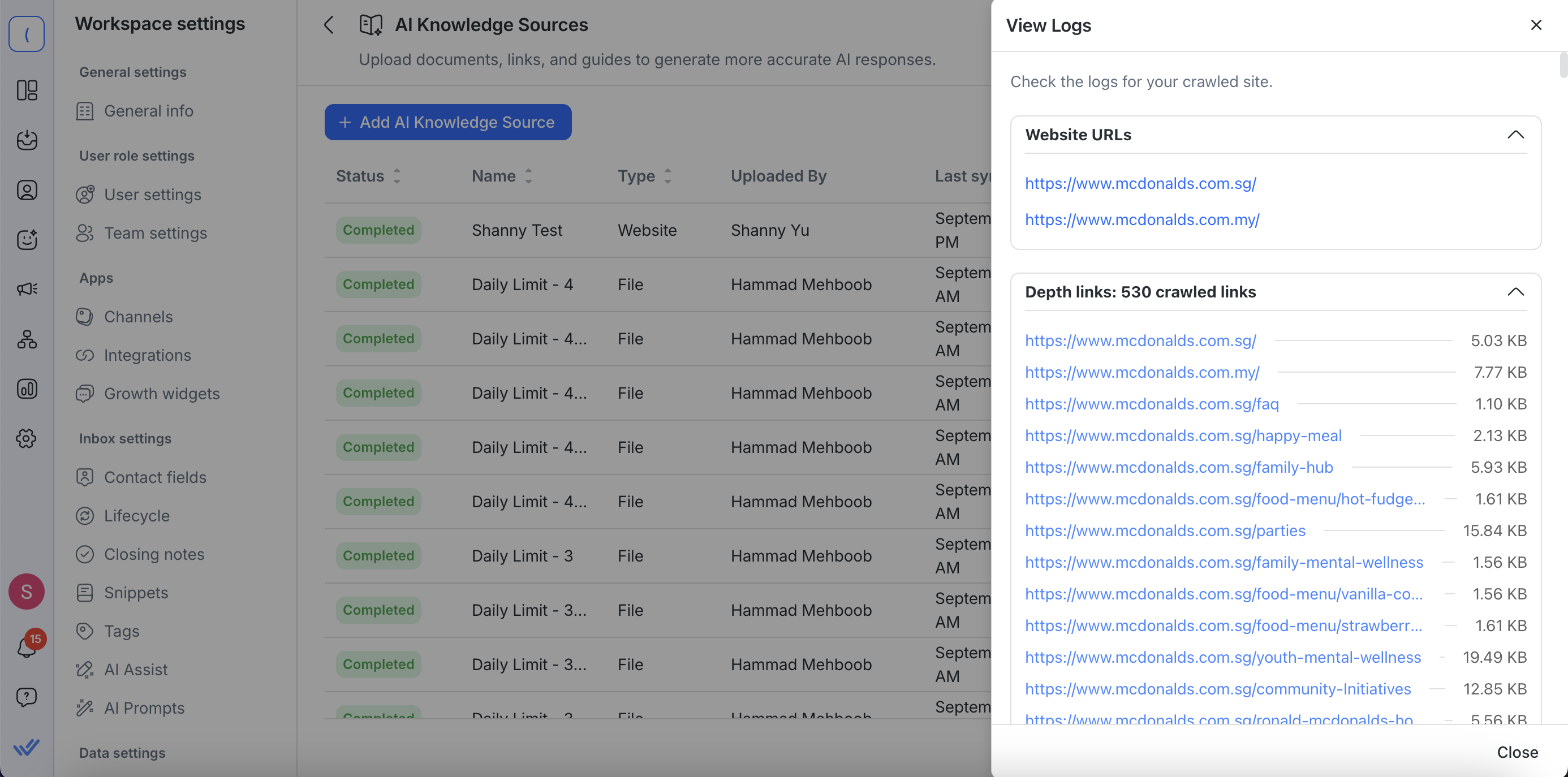
Просмотр журналов (для URL веб-сайтов)
Нажмите Действия > Просмотреть журналы, чтобы просмотреть подробности обхода источника знаний веб-сайта. Журналы дают вам полную видимость того, что было захвачено:
Начало и дополнительные URL – Смотрите URL-адреса веб-сайтов, которые вы ввели, вместе с любыми дополнительными URL, добавленными в Расширенных настройках.
Список всех обработанных ссылок – Каждая посещенная URL-адреса отображается.
Кликабельные ссылки — Каждая обработанная ссылка открывается в новой вкладке, чтобы вы могли просмотреть обрабатываемый контент непосредственно.
Размер извлеченного контента – Проверьте, сколько текста было извлечено с каждой страницы, отображается в КБ или МБ.
Это облегчает подтверждение того, что важные страницы были включены, выявление пропущенного или нерелевантного контента и устранение любых проблем с обходом.
Ресинхронизация веб-источников
Для обновления устаревшего веб-контента:
Нажмите Действия > Ресинхронизировать рядом с источником веб-сайта
Когда вы нажимаете Ресинхронизировать, процесс начинается немедленно, и появляется значок, показывающий, что он в процессе.
Вам придет уведомление, если повторная синхронизация не завершится полностью, например:
Достигнут лимит символов: исходный файл будет отображаться как Частично завершено, и весь контент, собранный в пределах лимита, будет сохранен
Ошибки таймаута или соединения: обход может остановиться раньше (максимум через 1 час), при этом частичное содержимое сохраняется, где это возможно.
Повторная синхронизация отключена, когда источник знаний активно синхронизируется.
Ограничения рабочего пространства для источников знаний AI
Чтобы все работало без сбоев, существуют ограничения на количество источников знаний, которые вы можете добавить, и на объем хранимого контента. Вот простое деление:
Общий размер хранения: до 20 МБ на рабочее пространство
Количество файлов: до 100 файловых источников знаний на рабочее пространство
Добавить/редактировать действия: до 50 изменений в день (добавление или редактирование источников)
Глубина сбора: Сбор веб-сайта идет по умолчанию на 3 уровня, но вы можете увеличить это до 100 уровней
Дополнительные URL-адреса сайта: вы можете добавить до 5 дополнительных URL-адресов на источник знаний
Если вы достигнете любого из этих лимитов, синхронизация и добавление новых источников приостановится, пока не освободится место или не сбросятся лимиты.
Ограничение Google Sheets
Google Sheets не поддерживается в качестве источника знаний для сайта. Добавление URL-адреса Google Sheets может привести к неточным или ненадёжным ответам ИИ.
Что ты можешь сделать
Скачайте Google Sheet в виде файла .csv.
Часто задаваемые вопросы и Устранение неполадок
Почему статус моего источника знаний по-прежнему отображает «В процессе»?
Большие веб-сайты или глубокие структуры ссылок требуют больше времени для сбора. Если он остается неизменным в течение нескольких часов, проверьте доступность URL (robots.txt, стены входа) или уменьшите глубину сбора.
Для загрузки файлов очень большие файлы или поврежденные документы также могут вызывать задержки. Если файл сложно обработать, попробуйте повторно загрузить более чистую версию в текстовом формате или другом поддерживаемом формате для более быстрой индексации.
Почему статус моего источника знаний показывает «Ошибка»?
Ошибки обычно происходят из-за поврежденных файлов, неподдерживаемых форматов, заблокированных веб-сайтов или тайм-аутов сервера. Чтобы это исправить, попробуйте заново загрузить контент в поддерживаемом формате (например, .pdf, .docx, .csv), проверьте доступность веб-сайта или повторите сбор.
Могу ли я загружать частные или внутренние ссылки?
Нет, поддерживаются только общедоступные URL-адреса. Для частного контента экспортируйте его как файл поддерживаемого типа (например, PDF, TXT) и загрузите файл.
Используют ли агенты AI автоматически все источники знаний?
Когда вы создаете или редактируете агента AI, все источники знаний в вашем рабочем пространстве перечислены. Вы выбираете, какие из них активировать, и только выбранные источники знаний будут использоваться для генерации ответов Контактам.
Могу ли я использовать Фрагменты как источник знаний для агентов AI?
Нет, в настоящее время фрагменты не поддерживаются как источник знаний для агентов AI. Если вы хотите видеть эту функцию в будущем, вы можете проголосовать за нее здесь.
Как часто я должен повторно синхронизировать веб-источники?
Синхронизируйте часто обновляемые сайты по расписанию (например, еженедельно или ежемесячно). Для статического контента достаточно ручных повторных синхронизаций.
Как мне предотвратить устаревшие или неактуальные ответы?
Заменяйте или удаляйте устаревшие источники, исключайте архивированные страницы с помощью шаблонов, и планируйте повторные синхронизации для часто обновляемого контента.
Почему я вижу ошибку "Too Many Requests" при сканировании источника знаний?
Это может произойти, если один и тот же источник знаний был просканирован и удалён более 50 раз в течение одного дня, что приводит к срабатыванию лимита запросов. Подожди 24 часа, затем снова попробуй просканировать источник знаний.
Чтобы не превысить лимит запросов, не добавляй, не удаляй и не добавляй заново один и тот же источник знаний в короткий промежуток времени.



